可重播的 Process Functions: Time, Ordering 和 Timers
— 焉知非鱼可重播的 Process Functions
利用流处理检测离线滑板车
在 Bird,一些最有趣的挑战涉及处理无桩物理硬件。不仅滑板车硬件可能出现故障,滑板车也可能被坏人偷走或破坏。我们从滑板车上收集遥测数据,但分析这些流水数据可能是一个挑战。
流处理自然适合从这些遥测数据中提取洞察力。我们使用 Flink 来处理来自 Kafka(我们的消息总线)的数据,运行寻找数据中不同信号的作业。Flink 提供了内置的工具来简化从 Kafka 的读取,并以容错的分布式方式处理数据流。Flink 还提供了大量内置的处理功能,以及用于自定义逻辑的各种构建块。
作为一家企业,Bird 需要跟踪我们硬件的健康状况。不健康的滑板车的一个症状是当它停止发送遥测记录。滑板车下线可能是由于电池问题、软件问题或硬件问题。我们需要知道何时发生这种情况,这样我们就可以尽快跟进。
我们写了一个 Flink 作业来检测滑板车何时离线,并很快遇到了一系列棘手的问题,涉及到 Kafka、事件时间、水印和排序。
Flink 的解决方法
Bird 将滑板车发送给我们的每条遥测记录称为轨迹。我们使用 Flink 作业来记录特定滑板车的每条轨迹的时间戳,并设置一个定时器,在一定的时间过后启动。如果我们在定时器启动之前看到另一条轨迹,我们就重置定时器以反映这个新轨迹的时间戳。如果我们没有看到另一条轨迹,定时器就会启动,我们就会输出一个事件,反映出这辆滑板车已经下线了。
遥测监测是一个自然的适合 keyed 的 process 函数,Flink 使得这项工作可以直接启动和运行。process 函数保持对滑板车 ID 的 keyed 状态,以跟踪当前的在线/离线状态,并通过事件时间定时器来处理离线检测。我们选择这条路线是因为我们想在以后用轨迹做更复杂的事情,并且想练习一下 process 函数,而不是仅仅使用一个会话窗口。
看上去很简单。但是,当我们测试这项工作对旧数据的表现时,我们遇到了一个障碍。当重放 Kafka 中的旧数据时,该作业同时输出了假阳性(它检测到虚假的离线事件)和假阴性(它错过了一些真正的离线事件)。
对这个问题的调查变得非常复杂,我们找到了一些有趣的解决办法,并将其应用于其他工作。我们了解到,关键是要理解。
-
为什么在回填(backfill)中排序是不可靠的
-
如何使用 Kafka 正确地提取时间戳和水印
-
以及定时器和 processElement 如何互动
从 Kafka 回填和数据排序
让我们从排序开始。我们有一个 Kafka 主题,有几个分区,没有特定的分区键。我们发现,在回填过程中,作业往往不会以相同的速度读取这些分区。我们最终会得到一个逻辑 Flink 流,其中的记录严重失序 - 几个小时甚至更久 请看下面的图表。
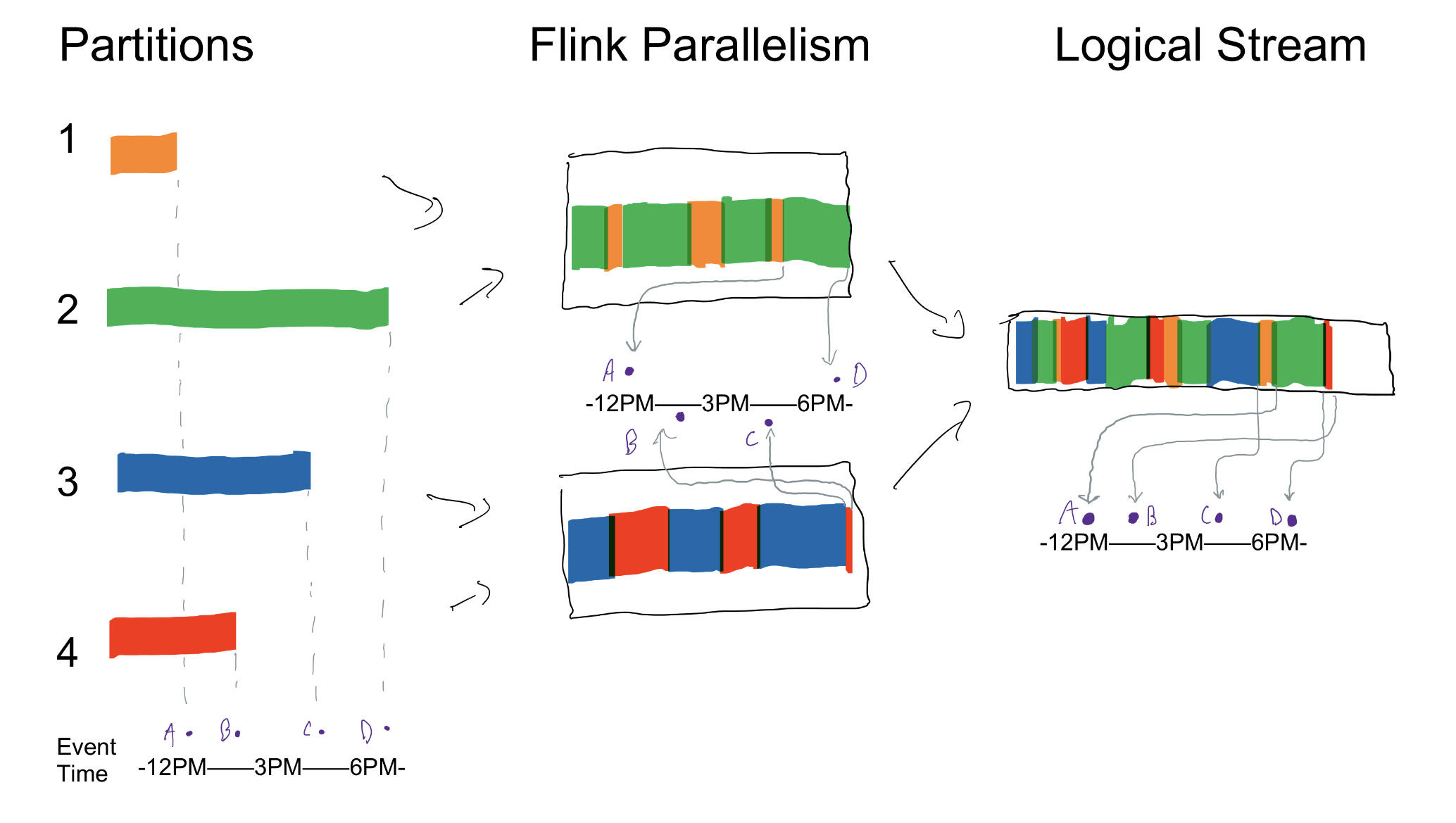
这张图代表了一个 job 的时间快照,它从一个有四个分区的 Kafka 主题中读取了6个多小时的数据。该作业的并行度为2,所以每个任务实例从两个分区读取数据。由于网络条件和每个实例与 broker 连接之间的其他差异,我们以极大的不同速率获得记录(例如,3点的记录在6点的记录之后出现,以此类推)。
水印
我们发现的第一件事是,我们没有正确提取我们的水印。Flink 的水印是解决这些问题的主要基石,所以我们必须首先解决这个问题。它们就像一个逻辑时钟,告诉 job 中的每一个 operator 我们在时间上走了多远。更多信息可以在这里阅读,在Flink 的文档中。幸运的是,这是一个简单的问题 - 但在我们看到这个失序的数据并开始调查如何解决它之前,我们已经错过了这里的文档中关于每个分区提取水印的全部意义。
我们的水印提取器是 BoundedOutOfOrdernessTimestampExtractor 的一个相当基本的实现。我们提供了一个从记录中提取时间戳的函数,库的代码通过从我们当前看到的最大时间戳中减去5秒来生成我们的水印。如果每条记录的时间戳最多比当前的最大时间戳晚五秒,那么这个方法就很有效。再晚的记录就被认为是迟到了,我们就把它们丢弃了。但是在我们的测试中,实时读取主题,我们没有看到任何迟到的记录。
考虑到不同的源分区读取速度,从 Kafka 读取时,水印需要以最慢的分区的速度前进。但我们看到有很多记录是在水印后面进来的。我们意识到,我们是在将 Kafka 源连接到流式执行环境之后才生成水印的,而不是之前。因此,在上图中,我们是在 “Flink Parallelism” 级别生成水印的。我们从分区1和分区2的组合流中抓取记录,并将这些记录作为我们新的水印候选者。因为水印不能向后移动,这意味着水印只被更快的分区,即分区2推进,所以它最终停留在(D)点。对于我们的另一个 job 实例,它同样是由分区3推进的,所以它最终停留在(C)点。当结合这两个时,Flink 采取了子任务水印的最小值 - 点(C)- 但这是在5点左右,比分区1和4的水印应该提前几个小时。
通过适当地将我们的水印提取移到 Kafka 源中,如上面的链接,我们得到了正确的水印。在上面的例子中,我们的水印在这个改变之后,最终出现在了(A)点而不是(C)点。
修复水印后,我们的定时器在回填过程中不再经常提前启动。它还阻止了我们在看到水印后面的数据时,错误地将其作为"晚到"数据丢弃。这一修正消除了很多假阳性的离线事件。
到目前为止,还不错,但移动水印提取并不能完全解决我们的排序问题。我们仍然有顺序逻辑的问题,即查看不符合顺序的数据,这可能给我们带来错误的否定。如果我们从看到1点的滑板车轨迹跳到3点的轨迹,我们就会失去检测这两个小时内可能发生的任何离线时间的能力。
在这一点上,我们重新审视了我们的几个基本决定。我们可以采取完全不同的方法 - 使用会话窗口而不是 process 函数,可以利用更多的内置逻辑来处理这些排序问题,但这个问题也影响了我们一些更复杂的工作,所以我们真的想让我们的 process 函数使用正确。
我们还研究了我们的 Kafka 设置。对于这个简单的案例,一个只读一个主题的作业,使用滑板车 ID 作为 Kafka 分区键可以保留滑板车的排序,但它并没有提供一个很好的通用解决方案 - 有些作业可能需要对相同的数据按不同的维度排序(比如按滑板车和按用户),而连接流也会带来同样的基本问题。所以我们想了解如何在 Flink 中更直接地处理这种行为。
第一次尝试: 事件时间窗口作为排序的缓冲器
我们的第一个想法是使用事件时间窗口来修复失序的数据。由于这些时间窗口是 Flink 的内置功能,我们认为它们可能是确保下游 process 函数排序的一个简单方法,而不必改变我们对顺序逻辑的 process 函数的使用。我们想,如果我们在函数之前添加非常短的事件时间窗口,数据就会按顺序传递下去。
一些测试证明了这种方法是正确的,但当我们使用事件时间窗口为离线作业部署缓冲时,我们遇到了一个意想不到的障碍 当回填数据时,与处理实时数据时相比,我们看到产生的离线事件仍然少了大约 10%。这个实施方案比我们以前的要好得多,但它仍然不是 100% 的。
当我们看了一些我们错过的时期后,我们发现了一个重要的线索。我们看到一个案例,我们检测到一辆滑板车离线了30分钟,然后在7秒后将其标记为在线。不知何故,在前一个轨迹30分钟7秒后的第二个轨迹导致我们的事件时间定时器(设置为第一个轨迹30分钟后)没有启动。
考虑一下下面一个滑板车的轨迹序列,以及我们想要设置的相应的30分钟后的定时器。
| Time | 30 Minutes Later |
|---|---|
| 17:30:15 | 18:00:15 |
| 17:30:20 | 18:00:20 |
| 17:30:25 | 18:00:25 |
| 18:00:32 | 18:30:32 |
Flink 的 KeyedProcessFunction 抽象类为我们提供了 processElement 和 onTimer 存根来覆盖。每当我们在 processElement 中看到一个滑板车的轨迹,我们就设置一个事件时间定时器,在30分钟后启动。随着我们看到更多的轨迹,这个定时器会不断地被推后。如果我们在30分钟内没有看到轨迹,当定时器启动时,onTimer 被调用,我们就会产生一个离线事件。如果我们在 processElement 中看到一个后续的轨迹,我们就会产生一个在线事件。
从上面的轨迹来看,我们希望这能像这样识别在线(蓝色)和离线(粉色)周期。

17:30:15、17:30:20 和 17:30:25 的轨迹将分别把超时时间推回到 18:00:15、18:00:20 和 18:00:25,依次进行。由于我们在 18:00:25 之前没有看到任何更多的轨迹,我们会在 18:00:25 触发一个离线事件。然后在 18:00:32,当我们收到那条轨迹时,我们会触发一个在线事件。
我们看到,这在实时数据中的效果是预期的,但在 18:00:25 的离线事件有时 - 但不总是 - 在回填中被错过。
定时器和事件时间与处理时间
我们最终发现,尽管我们认为我们所做的一切都基于事件时间,但这个问题是由于处理时间和事件时间语义的混合。这是两件事的结合。
-
我们使用的是周期性水印提取。每隔一段时间(默认为200ms),我们就会查看一条记录的时间戳,以便更新我们的水印。这种方法在实时情况下不会造成问题,但在回填时却会造成随机性。在回填中,我们读取记录的速度比实时快得多,所以在提取水印之间会有更多的事件时间。这种提高的读取速度意味着在200ms的间隔内会有更多的记录被读取,而水印相对于事件时间的落点就更不确定了。
-
事件定时器只在水印推进时启动。水印提取的非确定性意味着,当多次运行回填时,相对于运行过 processElement 的记录,事件定时器会在不同的点上启动。在回填的情况下,事件时间的快速移动意味着这可能会造成巨大的差异。
那么,离线作业回填,有时会在提取晚于 18:00:25 的水印之前,读取时间戳为 18:00:32 的记录。当这种情况发生时,我们立即将事件时间的定时器推到 18:30:32,所以我们从来没有产生我们期望看到的离线/在线对。
每一种类似的情况在回填中都有一些机会是不正确的。因此,我们的回填结果与我们的实时处理结果相互矛盾,也不一致。因此,我们面临的挑战是如何将水印驱动的定时器行为与 processElement 的即时性质同步。
我们有两个想法。第一种(也是最容易测试的方法)是在每条记录中生成水印,而不是只定期生成。用 Flink 术语来说,我们用 AssignerWithPunctuatedWatermarks 的实现而不是 AssignerWithPeriodicWatermarks 的实现来完成这个任务。而且,这确实摆脱了这个问题。
然而,这种方法有大量的处理开销,而且组件耦合度很高。我们现在需要更重的每条记录的水印提取器,加上我们需要包括缓冲事件的时间窗口,再加上处理函数本身。
让我们再考虑一下流中的预期失序问题。我们在前面提到过,在这里我们并不期望太多。我们的遥测数据在每个分区都是相当有序的,而且我们的水印提取器只有5秒的延迟,所以我们在实时数据中还没有真正注意到这一点。然而,它仍然可能发生,特别是如果我们要处理更多的无序数据,并在我们的水印提取中使用更高的延迟。(这是另一个地方,在那里,一个 keyed 的主题本身是不够的)。)
解决方案
相反,我们决定将缓冲嵌入到 process 函数中,并对每个元素进行异步缓冲处理。这被证明是一个相对简单的变化
我们的 processElement 函数现在
- 将每个传入的轨迹记录放在一个以其时间戳为 keyed 的 map 中,并
- 创建一个事件定时器,一旦水印到达该点就处理该记录。
当水印前进时,所有的定时器都按顺序启动。18:00:25 的定时器在 18:00:32 的缓冲轨迹之前启动。
在我们的 onTimer 回调中,我们检查两件事。
如果这个时间戳有一个缓冲轨迹:我们通过一个新的 handleTrack 函数来运行该轨迹,该函数包含之前由 processElement 执行的逻辑
如果这个定时器与我们当前的超时相匹配:我们就直接在 onTimer 中执行我们之前的逻辑。
通过在 process 函数中嵌入缓冲,我们能够使用事件时间来同步处理记录和定时器。
我们能够验证,这种缓冲记录的 process 函数解决方案能够带来确定性的输出,无论是对 Offline Birds 作业还是对其他使用 process 函数的作业都是如此 我们能够在 KeyedProcessFunction 的基础上,将这一修复方法概括为 BufferedKeyedProcessFunction 的抽象类,这样我们就可以与其他需要的作业分享这一修复方法。
一个缺点是,这种缓冲最终会占用大量的内存,并在进行时造成大量的检查点,因为分区的读取率会有很大的变化。但幸运的是,这也是 Flink 社区正在努力解决的问题,对具有平行分区的源进行读取时间调整。
事实证明,Flink 是一个很好的解决方案,它可以用流式逻辑来处理这些情况,但我们必须深入到如何处理时间的杂草中,才能找到回填问题的根源。现在我们理解了这个问题,我们已经将 BufferedKeyedProcessFunction 成功地应用于多个作业。我们希望通过分享我们的经验和学习在生产中操作 Flink 的一些关键应用,可以帮助其他人了解排序、水印和 process 函数都是如何互动的。