Flink 操作游乐场
— 焉知非鱼Flink Operations Playground
Flink 操作游乐场 #
在各种环境中部署和操作 Apache Flink 的方法有很多。无论这种多样性如何,Flink 集群的基本构件保持不变,类似的操作原则也适用。
在这个游乐场上,你将学习如何管理和运行 Flink Jobs。你将看到如何部署和监控应用程序,体验 Flink 如何从 Job 故障中恢复,并执行日常操作任务,如升级和重新缩放。
这个游乐场的解剖 #
这个游乐场由一个持久的 Flink Session Cluster 和一个 Kafka Cluster 组成。
一个 Flink Cluster 总是由一个 JobManager 和一个或多个 Flink TaskManager 组成。JobManager 负责处理 Job 提交,监督 Job 以及资源管理。Flink TaskManager 是 worker 进程,负责执行构成 Flink Job 的实际任务。在这个游戏场中,你将从单个 TaskManager 开始,但以后会扩展到更多的 TaskManager。此外,这个游乐场还带有一个专门的客户端容器,我们使用它来提交 Flink Job,并在以后执行各种操作任务。客户端容器不是 Flink Cluster 本身需要的,只是为了方便使用才包含在里面。
Kafka 集群由一个 Zookeeper 服务器和一个 Kafka Broker 组成。

当游乐场启动时,一个名为 Flink Event Count 的 Flink Job 将被提交给 JobManager。此外,还会创建两个 Kafka 主题 input 和 output。

该作业从 input 主题中消耗点击事件(ClickEvent),每个点击事件(ClickEvent)都有一个时间戳(timestamp)和一个页面(page)。然后按页面对事件进行分组(keyed by),并在 15 秒的窗口中进行计数。结果被写入 output 主题。
有6个不同的页面,我们在每个页面和15秒内产生1000个点击事件。因此,Flink 作业的输出应该显示每个页面和窗口有1000个浏览量。
启动游乐场 #
游戏场环境的设置只需几步。我们将引导你完成必要的命令,并展示如何验证一切都在正确运行。
我们假设你的机器上安装了 Docker(1.12+)和 docker-compose(2.1+)。
所需的配置文件可以在 flink-playgrounds 仓库中找到。检查一下,然后对齐环境。
git clone --branch release-1.11 https://github.com/apache/flink-playgrounds.git
cd flink-playgrounds/operations-playground
docker-compose build
docker-compose up -d
之后,你可以用以下命令检查正在运行的 Docker 容器。
docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------------------------------
operations-playground_clickevent-generator_1 /docker-entrypoint.sh java ... Up 6123/tcp, 8081/tcp
operations-playground_client_1 /docker-entrypoint.sh flin ... Exit 0
operations-playground_jobmanager_1 /docker-entrypoint.sh jobm ... Up 6123/tcp, 0.0.0.0:8081->8081/tcp
operations-playground_kafka_1 start-kafka.sh Up 0.0.0.0:9094->9094/tcp
operations-playground_taskmanager_1 /docker-entrypoint.sh task ... Up 6123/tcp, 8081/tcp
operations-playground_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
这表明客户端容器已经成功提交了 Flink Job(Exit 0),所有集群组件以及数据生成器都在运行(Up)。
你可以通过调用来停止游乐场环境。
docker-compose down -v
进入游乐场 #
在这个游乐场中,有很多东西你可以尝试和检查。在下面的两节中,我们将向你展示如何与 Flink 集群进行交互,并展示 Flink 的一些关键功能。
Flink WebUI #
观察你的 Flink 集群最自然的出发点是在 http://localhost:8081 下暴露的 WebUI。如果一切顺利,你会看到集群最初由一个 TaskManager 组成,并执行一个名为 Click Event Count 的 Job。
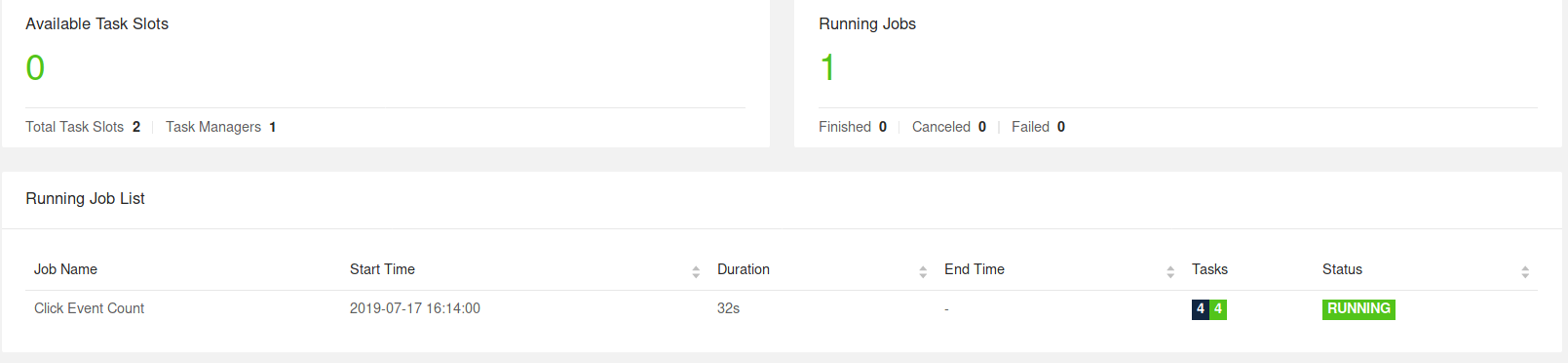
Flink WebUI 包含了很多关于 Flink 集群和它的工作的有用和有趣的信息(JobGraph, Metrics, Checkpointing Statistics, TaskManager Status, …)。
日志 #
JobManager #
可以通过 docker-compose 对 JobManager 日志进行跟踪。
docker-compose logs -f jobmanager
在初始启动后,你应该主要看到每一个检查点完成的日志信息。
TaskManager #
TaskManager 的日志也可以用同样的方式进行 tail。
docker-compose logs -f taskmanager
在初始启动后,你应该主要看到每个检查点完成的日志信息。
Flink CLI #
Flink CLI 可以在客户端容器中使用。例如,要打印 Flink CLI 的帮助信息,你可以运行以下命令
docker-compose run --no-deps client flink --help
Flink REST API #
Flink REST API 通过主机上的 localhost:8081 或客户端容器中的 jobmanager:8081 暴露出来,例如,要列出所有当前正在运行的作业,你可以运行:
curl localhost:8081/jobs
Kafka Topics #
你可以通过运行以下命令来查看写入 Kafka 主题的记录
//input topic (1000 records/s)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic input
//output topic (24 records/min)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
Time to Play! #
现在你已经学会了如何与 Flink 和 Docker 容器进行交互,让我们来看看一些常见的操作任务,你可以在我们的游乐场上尝试一下。所有这些任务都是相互独立的,即你可以以任何顺序执行它们。大多数任务可以通过 CLI 和 REST API 来执行。
列出正在运行的 Job #
- CLI
命令
docker-compose run --no-deps client flink list
期望的输出
Waiting for response...
------------------ Running/Restarting Jobs -------------------
16.07.2019 16:37:55 : <job-id> : Click Event Count (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
- REST API
请求
curl localhost:8081/jobs
期待的响应(美化了打印)
{
"jobs": [
{
"id": "<job-id>",
"status": "RUNNING"
}
]
}
JobID 在提交时被分配给作业(Job),并且需要通过 CLI 或 REST API 对作业(Job)执行操作。
观察故障和恢复 #
Flink 在(部分)失败下提供了精确的一次处理保证。在这个游乐场中,你可以观察并在一定程度上验证这种行为。
步骤1:观察输出
如上所述,在这个游乐场中的事件是这样生成的,每个窗口正好包含一千条记录。因此,为了验证 Flink 是否成功地从 TaskManager 故障中恢复,而没有数据丢失或重复,你可以跟踪 output 主题,并检查恢复后所有的窗口都存在,而且计数是正确的。
为此,从 output 主题开始读取,并让这个命令运行到恢复后(步骤3)。
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
第二步:引入故障
为了模拟部分故障,你可以杀死一个 TaskManager,在生产设置中,这可能对应于 TaskManager 进程、TaskManager 机器的丢失,或者仅仅是框架或用户代码抛出的瞬时异常(例如由于暂时不可用)。
docker-compose kill taskmanager
几秒钟后,JobManager 会注意到 TaskManager 的丢失,取消受影响的 Job,并立即重新提交它进行恢复。当 Job 被重新启动后,其任务仍处于 SCHEDULED 状态,由紫色的方块表示(见下面的截图)。
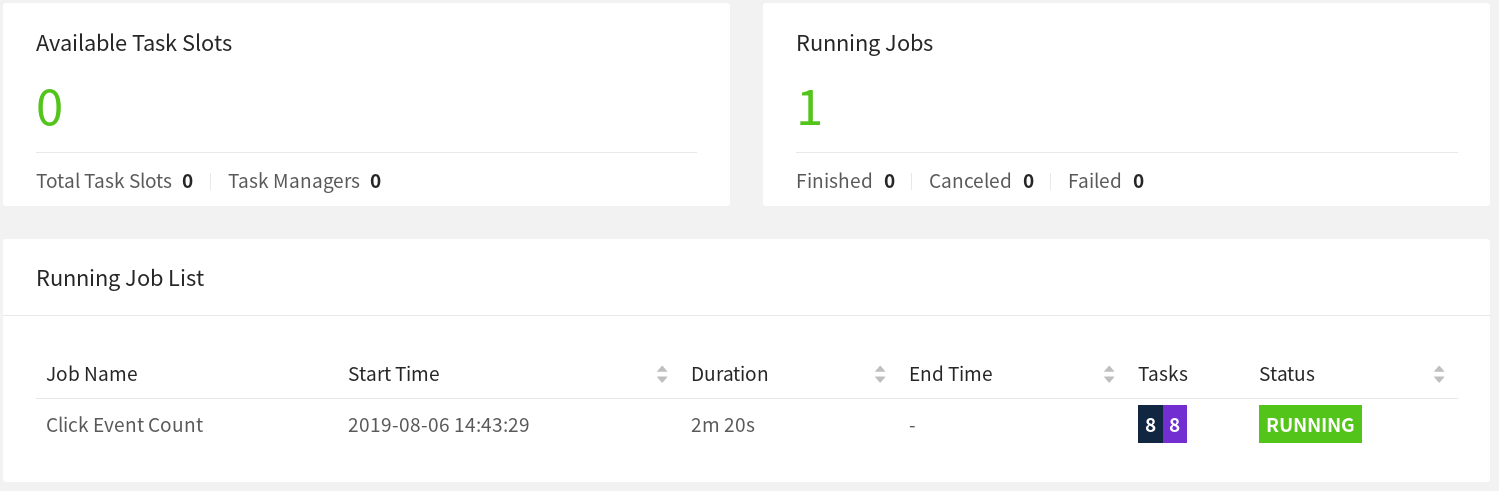
注意:即使作业(Job)的任务(Task)处于 SCHEDULED 状态而不是 RUNNING 状态,作业(Job)的整体状态也会显示为 RUNNING。
此时,Job 的任务(Task)不能从 SCHEDULED 状态转为 RUNNING 状态,因为没有资源(TaskManager 提供的 TaskSlots)来运行这些任务。在新的 TaskManager 可用之前,Job 将经历一个取消和重新提交的循环。
同时,数据生成器会不断地将 ClickEvents 推送到 input 主题中。这类似于真正的生产设置,在生产数据的同时,要处理数据的 Job 却宕机了。
步骤3:恢复
一旦你重新启动 TaskManager,它就会重新连接到 JobManager。
docker-compose up -d taskmanager
当 JobManager 被通知到新的 TaskManager 时,它将恢复中的 Job 的任务(tasks)调度到新的可用 TaskSlots。重新启动后,任务会从故障前最后一次成功的检查点恢复其状态,并切换到 RUNNING 状态。
Job 将快速处理来自 Kafka 的全部积压输入事件(在故障期间积累的),并以更高的速度(>24条记录/分钟)产生输出,直到到达流的头部。在输出中,你会看到所有的键(页面)都存在于所有的时间窗口中,而且每个计数都是精确的 1000。由于我们是在"至少一次"模式下使用 FlinkKafkaProducer,所以你有可能会看到一些重复的输出记录。
注意:大多数生产设置依赖于资源管理器(Kubernetes、Yarn、Mesos)来自动重启失败的进程。
升级和重新缩放作业 #
升级 Flink 作业总是涉及两个步骤。首先,用一个保存点优雅地停止 Flink Job。保存点是在一个明确定义的、全局一致的时间点(类似于检查点)上的完整应用状态的一致快照。其次,升级后的 Flink Job 从 Savepoint 开始。在这种情况下,“升级"可以意味着不同的事情,包括以下内容:
- 配置的升级(包括作业的并行性)。
- 对 Job 的拓扑结构进行升级(增加/删除 Operator)。
- 对 Job 的用户定义的函数进行升级。
在开始升级之前,你可能要开始 tailing output 主题,以观察在升级过程中没有数据丢失或损坏。
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
第一步:停止工作
要优雅地停止作业,你需要使用 CLI 或 REST API 的 “stop” 命令。为此,你需要该作业的 JobID,你可以通过列出所有正在运行的 Job 或从 WebUI 中获得。有了 JobID,你就可以继续停止该作业:
- CLI
命令
docker-compose run --no-deps client flink stop <job-id>
预期的输出
Suspending job "<job-id>" with a savepoint.
Suspended job "<job-id>" with a savepoint.
Savepoint 已经被存储到 flink-conf.yaml 中配置的 state.savepoint.dir 中,它被安装在本地机器的 /tmp/flink-savepoints-directory/ 下。在下一步中,你将需要这个 Savepoint 的路径。在 REST API 的情况下,这个路径已经是响应的一部分,你将需要直接查看文件系统。
命令
ls -lia /tmp/flink-savepoints-directory
预期的输出
total 0
17 drwxr-xr-x 3 root root 60 17 jul 17:05 .
2 drwxrwxrwt 135 root root 3420 17 jul 17:09 ..
1002 drwxr-xr-x 2 root root 140 17 jul 17:05 savepoint-<short-job-id>-<uuid>
- REST API
请求
# triggering stop
curl -X POST localhost:8081/jobs/<job-id>/stop -d '{"drain": false}'
预期的响应(美化了打印)
{
"request-id": "<trigger-id>"
}
请求
# check status of stop action and retrieve savepoint path
curl localhost:8081/jobs/<job-id>/savepoints/<trigger-id>
预期的响应(美化了打印)
{
"status": {
"id": "COMPLETED"
},
"operation": {
"location": "<savepoint-path>"
}
}
步骤2a: 重启 Job,不做任何改变
现在你可以从该保存点重新启动升级后的作业(Job)。为了简单起见,你可以在不做任何更改的情况下重新启动它。
- CLI
命令
docker-compose run --no-deps client flink run -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time
预期的输出
Starting execution of program
Job has been submitted with JobID <job-id>
- REST API
请求
# Uploading the JAR from the Client container
docker-compose run --no-deps client curl -X POST -H "Expect:" \
-F "jarfile=@/opt/ClickCountJob.jar" http://jobmanager:8081/jars/upload
预期的响应(美化了打印)
{
"filename": "/tmp/flink-web-<uuid>/flink-web-upload/<jar-id>",
"status": "success"
}
请求
# Submitting the Job
curl -X POST http://localhost:8081/jars/<jar-id>/run \
-d '{"programArgs": "--bootstrap.servers kafka:9092 --checkpointing --event-time", "savepointPath": "<savepoint-path>"}'
预期的输出
{
"jobid": "<job-id>"
}
一旦 Job 再次 RUNNING,你会在 output 主题中看到,当 Job 在处理中断期间积累的积压时,记录以较高的速度产生。此外,你会看到在升级过程中没有丢失任何数据:所有窗口都存在,数量正好是 1000。
步骤2b: 用不同的并行度重新启动作业(重新缩放)
另外,你也可以在重新提交时通过传递不同的并行性,从这个保存点重新缩放作业。
- CLI
docker-compose run --no-deps client flink run -p 3 -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time
预期的输出
Starting execution of program
Job has been submitted with JobID <job-id>
- REST API
请求
# Uploading the JAR from the Client container
docker-compose run --no-deps client curl -X POST -H "Expect:" \
-F "jarfile=@/opt/ClickCountJob.jar" http://jobmanager:8081/jars/upload
预期的响应(美化了打印)
{
"filename": "/tmp/flink-web-<uuid>/flink-web-upload/<jar-id>",
"status": "success"
}
请求
# Submitting the Job
curl -X POST http://localhost:8081/jars/<jar-id>/run \
-d '{"parallelism": 3, "programArgs": "--bootstrap.servers kafka:9092 --checkpointing --event-time", "savepointPath": "<savepoint-path>"}'
预期的响应(美化了打印)
{
"jobid": "<job-id>"
}
现在,作业(Job)已经被重新提交,但它不会启动,因为没有足够的 TaskSlots 在增加的并行度下执行它(2个可用,需要3个)。使用:
docker-compose scale taskmanager=2
你可以在 Flink 集群中添加一个带有两个 TaskSlots 的第二个 TaskManager,它将自动注册到 JobManager 中。添加 TaskManager 后不久,该任务(Job)应该再次开始运行。
一旦 Job 再次 “RUNNING”,你会在 output Topic 中看到在重新缩放过程中没有丢失数据:所有的窗口都存在,计数正好是 1000。
查询作业(Job)的指标 #
JobManager 通过其 REST API 公开系统和用户指标。
端点取决于这些指标的范围。可以通过 jobs/<job-id>/metrics 来列出一个作业的范围内的度量。指标的实际值可以通过 get query 参数进行查询。
请求
curl "localhost:8081/jobs/<jod-id>/metrics?get=lastCheckpointSize"
预期的响应(美化了打印; 没有占位符)
[
{
"id": "lastCheckpointSize",
"value": "9378"
}
]
REST API 不仅可以用来查询指标,还可以检索运行中的作业状态的详细信息。
请求
# find the vertex-id of the vertex of interest
curl localhost:8081/jobs/<jod-id>
预期的响应(美化了打印)
{
"jid": "<job-id>",
"name": "Click Event Count",
"isStoppable": false,
"state": "RUNNING",
"start-time": 1564467066026,
"end-time": -1,
"duration": 374793,
"now": 1564467440819,
"timestamps": {
"CREATED": 1564467066026,
"FINISHED": 0,
"SUSPENDED": 0,
"FAILING": 0,
"CANCELLING": 0,
"CANCELED": 0,
"RECONCILING": 0,
"RUNNING": 1564467066126,
"FAILED": 0,
"RESTARTING": 0
},
"vertices": [
{
"id": "<vertex-id>",
"name": "ClickEvent Source",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066423,
"end-time": -1,
"duration": 374396,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 0,
"read-bytes-complete": true,
"write-bytes": 5033461,
"write-bytes-complete": true,
"read-records": 0,
"read-records-complete": true,
"write-records": 166351,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "Timestamps/Watermarks",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066441,
"end-time": -1,
"duration": 374378,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 5066280,
"read-bytes-complete": true,
"write-bytes": 5033496,
"write-bytes-complete": true,
"read-records": 166349,
"read-records-complete": true,
"write-records": 166349,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "ClickEvent Counter",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066469,
"end-time": -1,
"duration": 374350,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 5085332,
"read-bytes-complete": true,
"write-bytes": 316,
"write-bytes-complete": true,
"read-records": 166305,
"read-records-complete": true,
"write-records": 6,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "ClickEventStatistics Sink",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066476,
"end-time": -1,
"duration": 374343,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 20668,
"read-bytes-complete": true,
"write-bytes": 0,
"write-bytes-complete": true,
"read-records": 6,
"read-records-complete": true,
"write-records": 0,
"write-records-complete": true
}
}
],
"status-counts": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 4,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"plan": {
"jid": "<job-id>",
"name": "Click Event Count",
"nodes": [
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEventStatistics Sink",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "FORWARD",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEvent Counter",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "HASH",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "Timestamps/Watermarks",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "FORWARD",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEvent Source",
"optimizer_properties": {}
}
]
}
}
请查阅 REST API 参考资料,了解可能查询的完整列表,包括如何查询不同作用域的指标(如 TaskManager 指标)。
变体 #
你可能已经注意到,Click Event Count 应用程序总是以 --checkpointing 和 --event-time 程序参数启动。通过在 docker-compose.yaml 的客户端容器的命令中省略这些,你可以改变 Job 的行为。
-
--checkpointing启用了 checkpoint,这是 Flink 的容错机制。如果你在没有它的情况下运行,并通过故障和恢复,你应该会看到数据实际上已经丢失了。 -
--event-time启用了你的 Job 的事件时间语义。当禁用时,作业将根据挂钟时间而不是 ClickEvent 的时间戳将事件分配给窗口。因此,每个窗口的事件数量将不再是精确的 1000。
Click Event Count 应用程序还有另一个选项,默认情况下是关闭的,你可以启用这个选项来探索这个作业在背压下的行为。你可以在 docker-compose.yaml 的客户端容器的命令中添加这个选项。