New Disp Is Here
— 焉知非鱼New Disp Is Here
大约 18 个月前,我开始着手进行 Raku 运行时 MoarVM 自成立以来最大的一组架构变化。这项工作最直接的起因是我们意识到,我们没有很好的方法来修复派发中的某个语义错误,而不会对整个系统的性能造成巨大的影响,也不会使已经在走运的优化中进一步增加复杂性。然而,对这种东西的需求在一段时间内是显而易见的:优化某些 Raku 语言特性的持续斗争,一堆性能机制的痛苦,这些机制都在解决同类问题,但每个都是针对特定的情况,以及一种感觉,即自从我创立 MoarVM 以来所学到的一切,都有可能做得更好。
其结果是开发了一个新的通用派发机制。简而言之,它为我们提供了一个更加统一的架构,适用于所有类型的派发,使我们能够在一系列的语言特性上提供更好的性能,而这些特性迄今为止一直是冰冷的,同时也为新的优化提供了机会。
今天,这项工作已经与 NQP(我们用于引导和实现编译器的 Raku 子集)和 Rakudo(完整的 Raku 编译器和标准库实现)中的相应变化合并。这意味着它将出现在2021年10月的版本中。
在这篇文章中,我将概述你可以立即观察到的情况,以及随着我们继续建立新的派发架构所提供的可能性,你可能会在未来期待什么。
大赢家 #
最大的改进涉及到我们以前确实没有架构可以做得更好的语言特性。它们涉及到派发 —— 也就是说,让调用有效地链接到目的地 —— 但运行时并没有为我们提供一种方法来"解释"它正在看一个派发,更不用说提供优化它所需的信息了。
下图捕捉了一些这样的案例,并显示了改进的程度,从3.3倍到13.3倍不等。
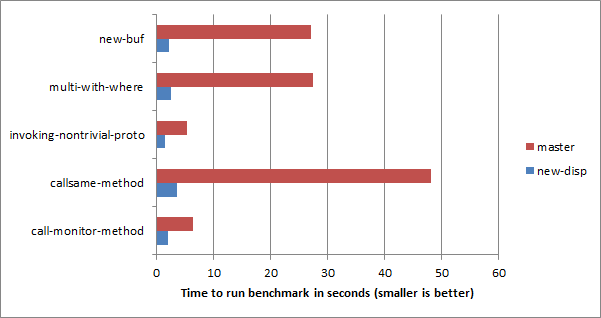
让我们快速看一下每一个问题。第一个,new-buf,问我们如何快速分配 Bufs。
for ^10_000_000 { Buf.new }
为什么说这是一个派发基准?因为 Buf 不是一个类,而是一个角色。当我们试图制造一个角色的实例时,它被 “punned” 成一个类。到现在为止,它的工作方式如下。
- 我们查找
new方法 - 如果需要的话,
find_method方法会创建一个角色的双关,并将其缓存起来 - 它将返回一个转发闭包,该闭包接受参数,并将其交给在被双关的类上调用的同一方法,或者写作 Raku 代码,
-> $role-discarded, |args { $pun."$name"(|args) } - 这个闭包将被调用,携带参数
这有一些不理想的后果。
- 虽然双关被缓存了,但我们仍然有一些开销来检查我们是否已经做了它。
- 参数被 slurp 和扁平化,这需要花费一些开销,而且……
- ……失去了
callite形状意味着我们无法查找方法的类型特化,因此也就失去了内联的机会。
有了新的派发机制,我们就有了在特定程序位置缓存常量和替换参数的方法。因此,当我们第一次遇到调用时,我们
- 如果需要的话,获得产生的角色双关
- 解决来自角色的类上的新方法的问题
- 产生一个派发程序,缓存这个已解决的方法,同时用双关替换角色参数。
在接下来的数千次调用中,我们解释这个派发程序。这仍然需要一些成本,但我们正在调用的方法已经被解决了,而且参数列表的重写也相当便宜。同时,在我们进入几百次迭代之后,在一个后台线程上,优化器开始工作。这时,参数重排的成本就完全消失了,而且新的参数非常小,可以被内联 —— 这时,缓冲区的分配被确定为无效,所以也就消失了。剩下的一些错过的机会意味着我们仍然留下了一个不完全是空的循环:它忙着确保它真的可以什么都不做,而不是什么都不做。
下一步,用 where 子句进行多重派发。
multi fac($n where $n <= 1) { 1 }
multi fac($n) { $n * fac($n - 1) }
for ^1_000_000 { fac(5) }
这些以前真的很慢,因为。
- 一旦有
where子句,我们就无法应用多派发缓存机制。 - 在候选者被选中的情况下,我们要运行两次
where子句:一次是看我们是否应该选择该多候选者,另一次是在我们进入该候选者时。
有了新的机制,我们:
- 在第一次调用时,计算出一个多重派发计划:一个需要处理的候选者的链接列表
- 调用带有
where子句的计划,在这种模式下,如果签名不能绑定,就会触发派发的恢复。(如果它绑定了,它就会运行到完成)。 - 如果绑定失败,则触发派发恢复,我们尝试下一个候选程序。
再一次,在设置阶段之后,我们解释派发程序。事实上,这就是我们目前运行速度较快的程度,因为专用程序还不知道如何翻译和进一步优化这种派发程序。(这就是为什么我知道它目前没有机会把这整个事情变成另一个空循环!)。) 因此,这里还有更多的东西可以利用;同时,恐怕你只能满足于10倍的速度。
这是下一个:
proto with-proto(Int $n) { 2 * {*} }
multi with-proto(Int $n) { $n + 1 }
sub invoking-nontrivial-proto() {
for ^10_000_000 { with-proto(20) }
}
同样,在顶层,我们也会把它变成一个空循环,但我们还没有达到这个目的。这种情况在以前并不可怕:我们确实可以使用多重派发缓存,但是为了做到这一点,我们也不得不分配一个参数捕获。这种需要也阻碍了将 proto 内联到调用者中的任何机会。现在这是有可能的。由于我们还不能翻译恢复正在进行的派发的派发程序,所以我们还不能进一步将被调用的多候选者内联到原语中。然而,我们现在有一个设计,可以让我们实现这一点。
这整个派发恢复的概念 —— 我们开始做一个派发,后来需要访问参数或其他预先计算的数据,以便进行下一步的派发 —— 已经被证明是一个伟大的统一。它的最初想法来自于考虑像 callame 这样的东西。
class Parent {
method m() { 1 }
}
class Child is Parent {
method m() { 1 + callsame }
}
for ^10_000_000 { Child.m; }
一旦我开始关注这个问题,然后考虑到一个复杂的 proto 也想在 {*} 处继续派发,并且在 where 子句在 multi 中失败的情况下,它也想继续派发,我意识到这对很多事情都会很有用。教导优化器和 JIT 对恢复做一些好的事情将是一个令人头痛的问题 —— 但是,做一次就能使多种语言特性受益,这让我感到非常欣慰。
总之,回到基准上。这是另一个"如果我们聪明的话,它就会是一个空循环"。以前,callsame 的成本很高,因为每次我们调用它时,它都必须计算出我们要恢复的是哪种派发以及要调用的方法集。我们还必须能够定位参数。涉及到动态变量,这也需要花费一些时间来查找,而且 —— 尽管是一个实现细节 —— 这些也会在自省中泄露出来,这并不理想。新的派发机制使这一切变得更有效率:我们可以缓存计算出的方法集(或包装器和 multi 候选方法,取决于上下文),然后走过它,而且不涉及动态变量(因此也不会泄露)。这体现了最大的速度提升 —— 由于我们还不能内联去掉调用名,它(目前)衡量的是人们在使用这种语言特性时可能期望的速度提升。 在未来,它注定会被优化为一个空循环。
OO::Monitors 是一个在相对较热的路径上使用 callame 的模块,所以我想看看那里是否也会有速度的提升。
use OO::Monitors;
monitor TestMonitor {
method m() { 1 }
}
my $mon = TestMonitor.new;
for ^1_000_000 { $mon.m(); }
monitor 是一个围绕每个方法调用获取锁的类。该模块提供了一个自定义的元类,为该类添加了一个锁属性,然后对每个方法进行包装,使其获得该锁。除了 callsame 的参与之外,当然还有一些昂贵的东西在里面,但是对 callsame 的改进已经足以让我们在这个基准中看到3.3倍的速度。由于 OO::Monitors 被用于相当多的应用程序和模块(例如,Cro 使用它),这是很受欢迎的(是的,这里也会有更大的改进)。
调用者端去容器化 #
我在其他一些微小测试中看到了一些不那么令人印象深刻,但仍然值得欢迎的改进。 即使是对 + 操作的基本多重派发。
my $i = 0;
for ^10_000_000 { $i = $i + $_; }
我们的速度提高了1.6倍,这主要归功于我们用更少的守卫产生了更紧密的代码。 以前,我们在这种看似简单的情况下会出现重复的防护措施。infix:<+> 多重选择将被专门用于其第一个参数是 Scalar 容器中的 Int,第二个参数是不可变的 Int 的情况。因为 Scalar 是可变的,所以这个特殊化需要读取它,然后在继续之前保护读取的值,否则它可能会改变,我们会有内存安全的风险。当我们想内联这个候选值时,我们也想检查一下这个候选值是否真的适用,所以也要遵从 Scalar,并对其内容进行保护来做到这一点。我们可以而且确实消除了重复的守卫 —— 但是这些守卫是对值的两次不同的读取,所以这没有帮助。
因为在新的派发机制中,我们可以重写参数,所以我们现在可以很容易地在调用方删除值周围的 Scalar 容器。事实上,这样做非常容易,我花了几个小时就完成了这个改动。这带来了很多好处。由于派发程序会自动消除重复的读取和守卫,多派发器的读取和守卫以及为了传递去容器化的值而进行的读取都会被凝聚起来。这意味着在专业化和 JIT 编译之前减少了重复的工作,而且在之后的专业化代码中也只有一个读和守。由于要传递的值已经被保护起来,我们可以简单地选择一个候选的两个 Int 值,这意味着在被调用者中也不需要再读和保护。
一个不太明显的好处是,这意味着 Scalar 容器逃逸到被调用方的情况要少得多,但在未来的工作中会变得很重要。这为逃逸分析创造了更多机会。虽然 MoarVM 的逃逸分析器和标量替换器目前还相当有限,但我希望在不久的将来能回到它的工作中,并期望它现在能给我们带来比以前更多的价值。
进一步的结果 #
前面显示的基准测试大多是"我们有多接近意识到我们有一个空循环"的性质,这对于评估优化器能多好地"看穿"派发是很有趣的。下面是一些在更"传统"的微基准上的进一步结果。
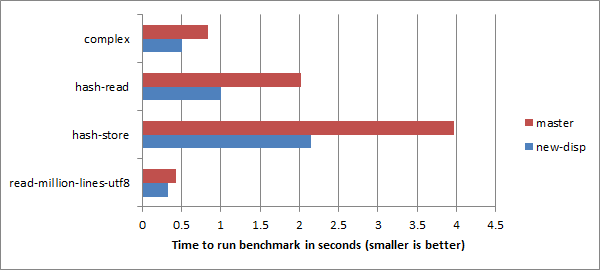
复数的基准是这样的:
my $total-re = 0e0;
for ^2_000_000 {
my $x = 5 + 2i;
my $y = 10 + 3i;
my $z = $x * $x + $y;
$total-re = $total-re + $z.re
}
say $total-re;
也就是说,只是一堆运算符(多派发)和方法调用,在这里我们确实使用了结果。目前,我们在这个基准上与 Python 并列,比 Ruby 稍稍落后(比用 Perl 的 Math::Complex 做同样的事情快了48倍,令人惊讶),但这也是一个在未来能看到逃逸分析和标量替换带来巨大好处的案例。
散列读取的基准是:
my %h = a => 10, b => 12;
my $total = 0;
for ^10_000_000 {
$total = $total + %h<a> + %h<b>;
}
而散列存储一个是:
my @keys = 'a'..'z';
for ^500_000 {
my %h;
for @keys { %h{$_} = 42; }
}
这些改进与哈希算法本身没有任何关系,相反,由于调用方的去容器化,看起来主要是由于更紧凑的代码。这可能有一个次要的影响,即把事情带到内联的大小限制之下,这也是一个很大的帮助。2倍和1.85倍的加速因子是值得欢迎的,尽管我们真的可以再做同样水平的改进,以便我对我们的结果感到合理的满意。
读取行的基准是:
my $fh = open "longfile";
my $chars = 0;
for $fh.lines { $chars = $chars + .chars };
$fh.close;
say $chars
同样,没有什么特定的 I/O 变得更快,但当派发 —— 把所有的部件组合在一起的胶水 —— 得到提升时,它就会帮助所有的地方。(我们在这个基准上也很有竞争力,尽管在 UTF-8 解码器不能采取它的"NFG 不可能应用"的快速路径时往往会慢一些)。)
而在不那么微观的事情上… #
我也开始关注更大的程序,并从其他人那里听到他们的结果。这大多是令人鼓舞的。
长期存在的 Text::CSV 基准 test-t 已经看到了大约 20% 的改进(感谢lizmat的测量)。
一个简单的 Cro::HTTP 测试程序每秒多了 10% 的请求。
MoarVM 的贡献者 dogbert 对一些脚本做了时间上的比较;最显著的改进看到从25秒下降到7秒,大多数都快了 10%-30%,有些没有变化,只有一个变慢了。
在标准库 CORE.setting 的编译上,有大约2.5%的改进。然而,这里需要一大把盐:作为工作的一部分,编译器本身在很多地方发生了变化,还有一些基于查看配置文件的东西进行了调整,这些东西与派发并不真正相关。
Agrammon,一个计算农业排放的应用程序,已经看到了大约9%的速度下降。我还没来得及仔细看,不过从剖析输出来看,取消优化的次数相对较多,这表明我们在某处做了一些不好的优化决定。
较小的剖析器输出 #
一个未曾预料到的(我)但也是值得欢迎的改进是,剖析器的输出已经明显变小。 可能的原因包括:
-
派发机制支持产生值结果(从常量、输入参数或从输入参数读取的属性)。它完全取代了早期的机制,即"特殊化插件",它可以将守卫映射到要调用的目标,但总是需要调用某个东西 —— 即使这个东西是身份函数。其逻辑是,这对任何真正的热代码来说并不重要,因为身份函数会被微不足道地内联掉。然而,由于仪器分析器的大小是通过调用树的路径数量的函数,从树中修剪对身份函数的调用负载会使它变小很多。
-
当一个值处于 sink 上下文时,我们曾经对
sink方法进行了大量的调用。现在,如果我们看到这个类型只是从 Mu 那里继承了这个方法,我们就会完全删除这个调用(同样,它会被内联掉,但是一个更小的调用图就是一个更小的配置文件)。
多重派发缓存以前总是在错过缓存时调用原语,但当它在未来得到缓存点击时,就不会再调用 onlystar 原语。这意味着许多多重派发下的调用树在配置文件中是重复的。这不仅仅是一个大小的问题;这种影响在配置文件的报告中也显示出来,这有点令人讨厌。
为了举例说明这种差别,我从 Agrammon 中提取了配置文件,以研究为什么它可能变得更慢。派发器工作之前的配置文件重达 87MB;而采用新的派发机制的配置文件则低于 30MB。这意味着剖析时使用的内存更少,事后将剖析结果写入磁盘的时间更短,工具加载剖析器输出的时间也更短。因此,现在可以更快地研究如何使事情变得更快。
有什么坏消息吗? #
恐怕是的。启动时间受到了影响。虽然新的派发机制更加强大,将更多的复杂性从虚拟机中推到了高级代码中,并且更有利于达到更高的峰值性能,但它也有更高的预热时间。在写这篇文章的时候,对启动时间的影响似乎是 25% 左右。我希望我们能在10月的发布之前收回一些。
什么会被打破? #
这种规模的变化总是伴随着一定的风险。我们将在下一次月度发布前几周进行合并,以便有时间进行更多的测试,并解决任何被报告的回归问题。然而,即使在达到合并的地步之前,我们已经。
- 确保它在正常情况下,以及在优化器压力下,都能通过规范测试套件(我们强迫它过早地优化一切,这样我们就能找出优化器的错误,以及 —— 考虑到我们强迫它做出的许多错误决定 —— 去优化的错误
- 使用
Blin来运行生态系统模块的测试。这是准备 Rakudo 发布时的一个标准步骤,但在这种情况下,我们把它放在new-disp分支上。这发现了一些由于切换到新的派发机制而引起的退步,这些问题已经被解决。 - 对一些依赖不支持的内部 API 的模块进行了补丁或发送了拉取请求,这些内部 API 现在已经消失或改变,或者依赖其他实现细节。这些模块相对较少,而且令人高兴的是,其中许多模块通过迁移到支持的 API(这些 API 在编写模块时可能并不存在)得到了修复。
接下来会发生什么? #
正如我在这篇文章中提到的一些地方,虽然有一些改进可以立即享受,但也有一些新的机会可以进一步改进。我想到的一些事情包括。
- 重新设计 callframe 的进入和退出。这些仍然是明显的成本过高。在研究新的派发机制时发生的各种变化,为这一领域的改进提供了新的机会。
- 避免巨变的堆积。微观基准在隐藏这些方面非常出色。事实上,这里的 “callsame” 就是一个完美的例子! 我们在
callsame中进行派发的恢复,所以整个程序中所有恢复的内联缓存条目都堆积在一个地方。我们所希望的是让它们在调用栈的下面一层连接起来。否则,在微观测试中看到的callsame水平的提高将无法在更大的应用中享受。 这也适用于其他一些情况。 - 应用新的派发机制来进一步优化结构。例如,一个方法调用的结果是调用特殊的
FALLBACK方法,它的调用点可以很容易地改写成这样,为内联开辟道路。 - 进一步调整我们在优化后产生的代码。有大量的浪费应该可以比较直接地消除,还有一些机会可以调整去优化,使我们能够删除更多的指令,并且仍然保留去优化的能力。
- 继续我之前做的逃逸分析工作,现在应该是比较有价值的了。更加灵活的
callstack/frame处理也应该解除我在标量替换Ints 方面的工作(在内存管理方面需要非常小心,因为它们可能会框住一个大的整数,而不仅仅是一个本地整数)。 - 实现特殊化、JIT 和派发恢复的内联。
感谢 #
我要感谢TPF和他们的捐助者提供的资金,使我有可能把大量的工作时间花在这项工作上。
虽然我对新派发机制的整体设计和大部分实现负有责任,但其他 MoarVM 和 Rakudo 的贡献者也付出了大量的工作 —— 特别是在过去的几个月里,随着最后的碎片落地,我们把注意力转移到让它为生产做好准备。我很感谢他们,不仅是对代码和调试的贡献,还有一路走来的支持和鼓励。合并的感觉很好,我期待着在未来的几个月和几年里在此基础上继续发展。
https://6guts.wordpress.com/2021/09/29/the-new-moarvm-dispatch-mechanism-is-here/