Spark Structured Streaming 中的持续执行
— 焉知非鱼这些年来,Apache Spark 的流媒体被认为是与微批处理一起工作的。但是,版本 2.3.0 试图对此进行更改,并提出了一种称为“连续”的新执行模型。即使它仍处于实验状态,还是值得更多了解它。
这篇文章介绍了连续流处理的新实验功能。第一部分解释并与微批执行策略进行比较。下一个显示一些内部细节。在第三部分中,我们可以了解至少一次保证。最后一部分在基于比率的源示例中显示了一个简单的连续执行用例。
连续流 #
毕竟为什么要替换微批处理的 Spark 区别标记(与允许连续流处理的 Apache Flink 或 Apache Beam 不同)?答案很简单-延迟。使用微批处理时,延迟很高。在最坏的情况下,等待时间是批处理时间与任务启动时间的总和,估计为几毫秒。连续处理将数据到达与其处理之间的等待时间减少到几毫秒。延迟减少是此(仍)实验特性背后的主要动机。
从鸟瞰来看,连续查询在多个线程中执行。每个线程负责不同的分区。因此,为了保证最佳的并行性,集群中可用核心的数量必须等于要处理的分区的数量。在处理期间,这些线程将结果连续写入结果表。
从技术上讲,可以通过 .trigger(Trigger.Continuous("1 second")) 使用连续触发来启用连续处理。但必须强调的是,在当前(2.3.0)Spark 版本中,并非所有操作都暴露于此模式下。在可用的转换中,我们只能区分投影(select,映射函数)和选择(过滤器子句)。
但是,降低延迟并不是没有代价的。实际上,更快的处理将交付保证从正好一次下降到了至少一次。因此,对于处理延迟比交付保证更为重要的系统,建议执行连续执行。
ContinuousExecution 类 #
最初,在结构化流中,StreamExecution 包含整个执行逻辑。仅在 2.3.0 版本中,它才成为由 MicroBatchExecution 和 ContinuousExecution 扩展的抽象类。这两个类的出发点都是 org.apache.spark.sql.execution.streaming.StreamExecution#runStream(),在执行一些初始化步骤之后,该类将激活每个执行策略中实现的流查询,方法为 runActivatedStream(sparkSessionForStream: SparkSession)` 方法。
由于以下代码,ContinuousExecution 连续运行查询:
do {
runContinuous(sparkSessionForStream)
} while (state.updateAndGet(stateUpdate) == ACTIVE)
在此 runContinuous 方法内部,发生了许多操作。第一个步骤包括将查询逻辑计划转换为一系列 ContinuousReaders。此接口定义是否可以连续方式读取给定的数据源。当前仅支持 Apache Kafka 和基于速率的源(该源以固定的Y间隔每秒生成 X(行,计数器)行,其中 X 和 Y 是配置参数)。如果某些源或操作不支持连续模式,则在启动查询之前会引发 UnsupportedOperationException。
在创建源之后,将解析起始偏移量,以确定何时开始执行给定执行的处理。如果查询是第一次启动,则偏移量自然为空。但是,再次执行查询时,将从提交日志中检索偏移量。稍后,将为每个映射到读取偏移量的数据源创建一个 StreamingDataSourceV2Relation 实例。接下来,创建数据读取器和写入器,并以与微批处理方法完全相同的方式生成执行计划。
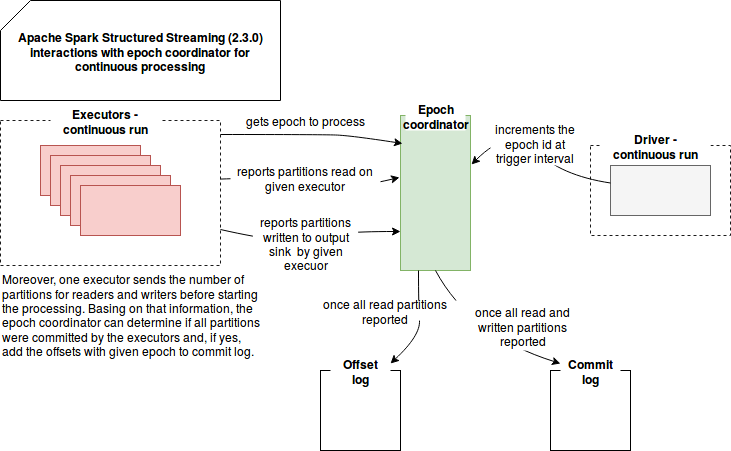
在下一步中,引擎通过 EpochCoordinator 实例以纪元(与微批处理中的批处理类似)进行播放。这是连续处理的杰作。此 RPC 端点负责处理以下消息:
- 生成新的纪元ID-通过消息 IncrementAndGetEpoch,该纪元 ID 会自动增加。然后,在 runContinuous 方法中返回新值。
- 返回当前纪元ID-表示为 GetCurrentEpoch 实例的此 getter 消息由定期执行 EpochPollRunnable 中定义的逻辑的线程使用。在此逻辑中,引擎检索当前已知的纪元并将其添加到要处理的消息的内部队列中。在此列表下面的模式中将对此进行详细说明。
- 在纪元下提交分区-在给定时期内对分区的处理终止时,会将 CommitPartitionEpoch 消息发送给 EpochCoordinator 以发出信号。如果所有纪元的分区都已处理,则 ContinuousExecution 将此纪元标记为已提交。这意味着该纪元被保留在提交日志中,并且在重新处理的情况下,与之关联的偏移量被用作起始偏移量(请参见上一段)。
这些涉及纪元协调器的连续处理逻辑可以在以下简化模式中恢复:
至少一次保证 #
您可能想知道为什么连续模式至少一次保证? 如前所述,主要理由是减少延迟。 在代码中,它是在解析每个源的起始偏移量的那一刻进行翻译的。 您可以在以下模式中看到这一点,该模式显示了微批处理和连续处理的执行的最初时刻:
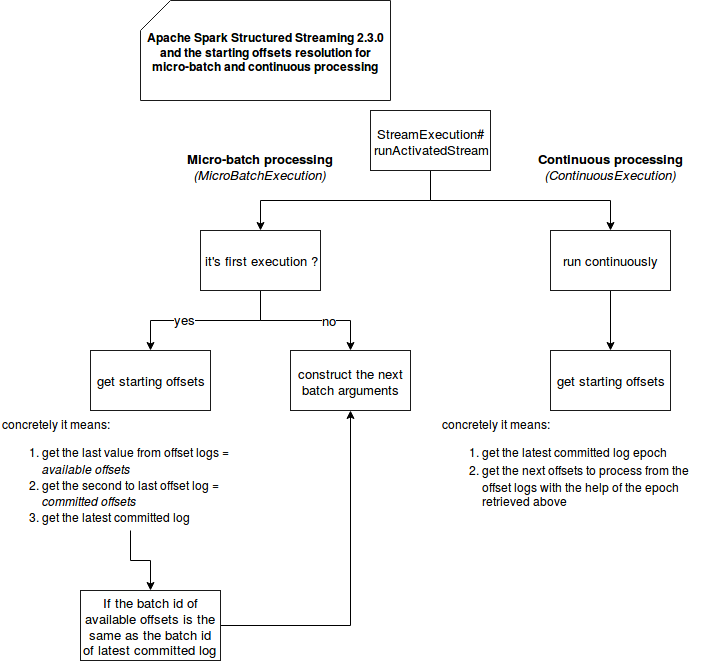
如您所见,两种模式的起始偏移量生成都略有不同。微批处理基于偏移日志和提交日志,而连续批处理仅使用提交日志。从写入部分(图中未显示)开始,偏移量始终在提交日志之前保留。仅在成功处理给定纪元或微批处理后,才保存后一个。鉴于两种处理的写作工作流程相同,因此阅读部分的差异突出了连续策略中的至少一次保证。
要理解它,没有什么比一个示例更好。假设提交日志中的最后一个批处理/纪元ID是#2,并且它对应于偏移量(4、5、6)(= 3个Kafka分区)。偏移日志中的最新值是(7、8、9),它们对应于批次/时期#3。现在,连续执行将读取提交日志,并查看最后一个时期#2。然后,它检索与其对应的偏移量((4,5,6))。因此它将重新处理(4,5,6)。微批处理执行更多步骤。首先,它获取最后的偏移量日志((7,8,9))。接下来,将它们与最后提交的偏移量((4,5,6))进行比较。由于两者具有不同的批次ID,因此保留与最新批次ID对应的偏移量以进行处理。
偏移细微差别 #
实际上,Apache Spark 结构化流处理的偏移范围包括:开始偏移(包括)和结束偏移(不包括)。结束偏移量用作下一个处理的起点。您可以在 org.apache.spark.sql.sql.kafka010.KafkaSource#getBatch 中根据注释查看该实例:“返回偏移量之间的数据[start.get.partitionToOffsets,end.partitionToOffsets) ,即 end.partitionToOffsets 是互斥的。”
上面示例中的单个值仅用于简化情况。
连续处理实例 #
以下片段中呈现的用例将很快介绍连续处理:
"continuous execution" should "execute trigger at regular interval independently on data processing" in {
val messageSeparator = "SEPARATOR"
val logAppender = InMemoryLogAppender.createLogAppender(Seq("New epoch", "has offsets reported from all partitions",
"has received commits from all partitions. Committing globally.", "Committing batch"),
(loggingEvent: LoggingEvent) => LogMessage(s"${loggingEvent.timeStamp} ${messageSeparator} ${loggingEvent.getMessage}", ""))
val rateStream = sparkSession.readStream.format("rate").option("rowsPerSecond", "10")
.option("numPartitions", "2")
val numbers = rateStream.load()
.map(rateRow => {
// Slow down the processing to show that the epochs don't wait commits
Thread.sleep(500L)
""
})
numbers.writeStream.outputMode("append").trigger(Trigger.Continuous("2 second")).format("memory")
.queryName("test_accumulation").start().awaitTermination(60000L)
// A sample output of accumulated messages could be:
// 13:50:58 CET 2018 : New epoch 1 is starting.
// 13:51:00 CET 2018 : New epoch 2 is starting.
// 13:51:00 CET 2018 : Epoch 0 has offsets reported from all partitions: ArrayBuffer(
// RateStreamPartitionOffset(1,-1,1521958543518), RateStreamPartitionOffset(0,-2,1521958543518))
// 13:51:00 CET 2018 : Epoch 0 has received commits from all partitions. Committing globally.
// 13:51:01 CET 2018 : Committing batch 0 to MemorySink
// 13:51:01 CET 2018 : Epoch 1 has offsets reported from all partitions: ArrayBuffer(
// RateStreamPartitionOffset(0,24,1521958546118), RateStreamPartitionOffset(1,25,1521958546118))
// 13:51:01 CET 2018 : Epoch 1 has received commits from all partitions. Committing globally.
// 13:51:01 CET 2018 : Committing batch 1 to MemorySink
// 13:51:02 CET 2018 : New epoch 3 is starting.
// 13:51:04 CET 2018 : New epoch 4 is starting.
// 13:51:06 CET 2018 : New epoch 5 is starting.
// 13:51:08 CET 2018 : New epoch 6 is starting.
// As you can see, the epochs start according to the defined trigger and not after committing given epoch.
// Even if given executor is in late for the processing, it polls the information about the epochs regularly through
// org.apache.spark.sql.execution.streaming.continuous.EpochPollRunnable
var startedEpoch = -1
var startedEpochTimestamp = -1L
for (message <- logAppender.getMessagesText()) {
val Array(msgTimestamp, messageContent, _ @_*) = message.split(messageSeparator)
if (messageContent.contains("New epoch")) {
// Here we check that the epochs are increasing
val newEpoch = messageContent.split(" ")(3).toInt
val startedNewEpochTimestamp = msgTimestamp.trim.toLong
newEpoch should be > startedEpoch
startedNewEpochTimestamp should be > startedEpochTimestamp
startedEpoch = newEpoch
startedEpochTimestamp = startedNewEpochTimestamp
} else if (messageContent.contains("Committing globally")) {
// Here we prove that the epoch commit is decoupled from the starting of the new
// epoch processing. In fact the new epoch starts according to the delay defined
// in the continuous trigger but the commit happens only when all records are processed
// And both concepts are independent
val committedEpoch = messageContent.split(" ")(2).toInt
startedEpoch should be > committedEpoch
msgTimestamp.trim.toLong should be > startedEpochTimestamp
}
}
}
连续处理是 Apache Spark 向社区提出的另一个有趣的解决方案。 通过经典的面向微批处理的执行,流处理具有一次保证的能力。 但是,如第一部分所示,代价是等待时间。 连续处理是一种替代方法,可以牺牲一次保证以减少等待时间。 正如在接下来的2部分中介绍的那样,它通过将 StreamExecution 类分成代表每个策略的 2 个类来进行传递。 在连续执行的情况下,差异取决于偏移量分辨率。 它仅基于提交日志,而在微批处理的情况下,将偏移日志和提交日志混合使用以减少不必要的重新处理。 最后一部分介绍了使用连续执行的简单测试案例。