Spark Structured Streaming 中的容错
— 焉知非鱼结构化流可通过应用于状态管理,数据源和数据接收器的语义来保证端到端的一次精确交付(以微批处理模式)。关于状态的帖子更详细地介绍了状态,但还有2个其他部分尚待发现。
这篇文章分为2个主要部分。第一部分着眼于数据源,并说明了在微批量处理的情况下,一旦交付,它们将如何对端到端做出贡献。第二部分是关于接收器的部分,而最后一部分则是在一个示例中总结了所有理论要点。
数据源 #
就正好一次处理而言,源必须是可重播的。也就是说,它必须允许跟踪当前的读取位置,还必须从上一个故障位置开始重新处理。这两个属性都有助于在任意失败(包括 driver 或 executor)后恢复处理状态。可重播源的一个很好的例子是 Apache Kafka 或其基于云的同事 Amazon Kinesis。两者都能够跟踪当前读取的元素-带偏移量的 Kafka 和带序列号的 Kinesis。不可重播源的一个很好的例子是 org.apache.spark.sql.execution.streaming.MemoryStream,在关闭应用程序后由于数据存储在易失性内存中而无法恢复。
借助检查点机制,可以跟踪已处理的偏移量。在结构化流中,检查点文件中存储的项主要是有关当前批次中处理的偏移量的元数据。检查点存储在 checkpointLocation 选项或 spark.sql.streaming.checkpointLocation 配置条目中指定的位置。
对于微批量执行,检查点将集成在以下架构中:
- 检查点位置通过 StreamingQueryManager的startQuery 和 createQuery 方法从 DataStreamWriter#startQuery() 方法传递到 StreamExecution 抽象类。
- StreamExecution 初始化对象 org.apache.spark.sql.execution.streaming.OffsetSeqLog。该对象表示 WAL日志,该日志记录每个已处理批次中存在的偏移量。 该字段表示处理数据源中偏移量的逻辑。当前微批处理的偏移量(我们称其为 N)始终在处理完成之前写入。该事实还假定来自先前微批处理(N-1)的所有数据均已正确写入输出接收器。在以下来自 org.apache.spark.sql.execution.streaming.MicroBatchExecution#constructNextBatch() 的代码段中进行了表示:
updateStatusMessage("Writing offsets to log")
reportTimeTaken("walCommit") {
assert(offsetLog.add(
currentBatchId,
availableOffsets.toOffsetSeq(sources, offsetSeqMetadata)),
s"Concurrent update to the log. Multiple streaming jobs detected for $currentBatchId")
logInfo(s"Committed offsets for batch $currentBatchId. " +
s"Metadata ${offsetSeqMetadata.toString}")
// NOTE: The following code is correct because runStream() processes exactly one
// batch at a time. If we add pipeline parallelism (multiple batches in flight at
// the same time), this cleanup logic will need to change.
// Now that we've updated the scheduler's persistent checkpoint, it is safe for the
// sources to discard data from the previous batch.
if (currentBatchId != 0) {
val prevBatchOff = offsetLog.get(currentBatchId - 1)
if (prevBatchOff.isDefined) {
prevBatchOff.get.toStreamProgress(sources).foreach {
case (src: Source, off) => src.commit(off)
case (reader: MicroBatchReader, off) =>
reader.commit(reader.deserializeOffset(off.json))
}
} else {
throw new IllegalStateException(s"batch $currentBatchId doesn't exist")
}
}
// It is now safe to discard the metadata beyond the minimum number to retain.
// Note that purge is exclusive, i.e. it purges everything before the target ID.
if (minLogEntriesToMaintain < currentBatchId) {
offsetLog.purge(currentBatchId - minLogEntriesToMaintain)
commitLog.purge(currentBatchId - minLogEntriesToMaintain)
}
}
如果流查询开始时偏移检查点文件已经存在,则引擎尝试在 populateStartOffsets(sparkSessionToRunBatches: SparkSession) 中检索以前处理的偏移。解析算法通过以下步骤完成: 解析当前批次的 ID,要处理的偏移量(来自第 N 个检查点文件)以及 N-1 个批次中提交的偏移量。此时,第 N 个批次的偏移量被视为可用于处理,而 N-1 个批次的偏移量已被视为已提交 确定当前的实际批次。当第 N 个偏移量的批次 ID 与提交日志中最后写入的批次 ID 相同时,引擎会将偏移量设置为已提交的偏移量,并将批次 ID 递增 1。然后通过查询接收器重新计算新的微批次。用于处理新的偏移量。 否则,解析的微批处理将被视为实际的当前批处理,并且处理将从偏移量开始到处理。
要完全理解此过程,重要的是还要知道什么是提交日志。由于它与接收器更相关,因此将在下一部分中详细介绍。
数据接收器 #
提交日志是 WAL,用于记录已完成批次的 ID。它用于检查给定的批次是否已完全处理,即是否已读取所有偏移量以及是否将输出提交给接收器。在内部,它表示为 org.apache.spark.sql.execution.streaming.CommitLog,并在处理下一个触发器之前立即执行,如以下模式所示:
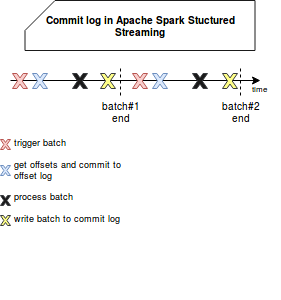
实际上,无论是可重播的源代码还是提交日志都不能保证一次处理本身。如果批处理提交失败怎么办?如前所述,引擎将检测到最后提交的偏移量作为要重新处理的偏移量,并将处理后的数据再次输出到接收器。显然,这将导致输出重复。但是只有当写入和接收器不是幂等时,情况才会如此。
幂等写是为给定输入生成相同写数据的写。幂等接收器是仅写入给定生成的行一次(即使多次发送)的系统。键值数据存储就是一个很好的例子。现在,如果编写器是幂等的,显然每次都会生成相同的键,并且由于行标识是基于键的,因此整个过程都是幂等的。与可重播源一起,它可以确保一次精确的端到端处理。
正好一次处理示例 #
为了查看一次精确的端到端处理如何工作,我们将以一个简单的文件示例为例,该文件经过转换并写回另一个目录中的另一个文件中。为了说明故障并由此说明容错性,条目的第一次处理将失败:
override def beforeAll(): Unit = {
Path(TestConfiguration.TestDirInput).createDirectory()
Path(TestConfiguration.TestDirOutput).createDirectory()
for (i <- 1 to 10) {
val file = s"file${i}"
val content =
s"""
|{"id": 1, "name": "content1=${i}"}
|{"id": 2, "name": "content2=${i}"}
""".stripMargin
File(s"${TestConfiguration.TestDirInput}/${file}").writeAll(content)
}
}
override def afterAll(): Unit = {
Path(TestConfiguration.TestDirInput).deleteRecursively()
Path(TestConfiguration.TestDirOutput).deleteRecursively()
}
"after one failure" should "all rows should be processed and output in idempotent manner" in {
for (i <- 0 until 2) {
val sparkSession: SparkSession = SparkSession.builder()
.appName("Spark Structured Streaming fault tolerance example")
.master("local[2]").getOrCreate()
import sparkSession.implicits._
try {
val schema = StructType(StructField("id", LongType, nullable = false) ::
StructField("name", StringType, nullable = false) :: Nil)
val idNameInputStream = sparkSession.readStream.format("json").schema(schema).option("maxFilesPerTrigger", 1)
.load(TestConfiguration.TestDirInput)
.toDF("id", "name")
.map(row => {
val fieldName = row.getAs[String]("name")
if (fieldName == "content1=7" && !GlobalFailureFlag.alreadyFailed.get() && GlobalFailureFlag.mustFail.get()) {
GlobalFailureFlag.alreadyFailed.set(true)
GlobalFailureFlag.mustFail.set(false)
throw new RuntimeException("Something went wrong")
}
fieldName
})
val query = idNameInputStream.writeStream.outputMode("update").foreach(new ForeachWriter[String] {
override def process(value: String): Unit = {
val fileName = value.replace("=", "_")
File(s"${TestConfiguration.TestDirOutput}/${fileName}").writeAll(value)
}
override def close(errorOrNull: Throwable): Unit = {}
override def open(partitionId: Long, version: Long): Boolean = true
}).start()
query.awaitTermination(15000)
} catch {
case re: StreamingQueryException => {
println("As expected, RuntimeException was thrown")
}
}
}
val outputFiles = Path(TestConfiguration.TestDirOutput).toDirectory.files.toSeq
outputFiles should have size 20
val filesContent = outputFiles.map(file => Source.fromFile(file.path).getLines.mkString(""))
val expected = (1 to 2).flatMap(id => {
(1 to 10).map(nr => s"content${id}=${nr}")
})
filesContent should contain allElementsOf expected
}
object TestConfiguration {
val TestDirInput = "/tmp/spark-fault-tolerance"
val TestDirOutput = s"${TestDirInput}-output"
}
object GlobalFailureFlag {
var mustFail = new AtomicBoolean(true)
var alreadyFailed = new AtomicBoolean(false)
}
通过可重播的源,容错状态管理,幂等接收器,Apache Spark 结构化流保证了一次准确的传递语义。 如本文所示,它通过检查点来实现。 对于源,引擎检查点会指定可用的偏移量,这些偏移量以后可以转换为已处理的偏移量。 在接收器的情况下,在数据处理后将成功批处理的 ID 提交给提交日志时,将由提交日志提供容错功能。 最后的第三部分显示了两个部分如何协同工作以提供恰好一次的处理。