Networking and Sockets: Endianness
在我之前的文章中,我们介绍了关于网络和套接字的一些基本概念。我们讨论了不同的模型,并使用套接字创建了一个简单的网络通信示例,特别是从 Stream TCP 套接字开始。
我们选择这种套接字类型及其家族,因为它是最常见的实现之一,也是大多数开发人员最常用的。Stream TCP 套接字因其可靠性和建立面向连接的通信通道的能力而被广泛使用。这使得它们在数据完整性和顺序性至关重要的场景中非常理想,如网页浏览、电子邮件和文件传输。通过了解 Stream TCP 套接字的基础知识,开发人员可以构建健壮的网络应用程序并更有效地排除故障。
在本文中,我们将继续使用这种套接字类型,深入探讨套接字编程。到目前为止,我们已经看到了如何创建一个作为服务器的监听套接字以及如何使用另一个套接字连接到它。现在,我们将探索这种通信的一个关键细节——字节序(endianness)!
Endianness
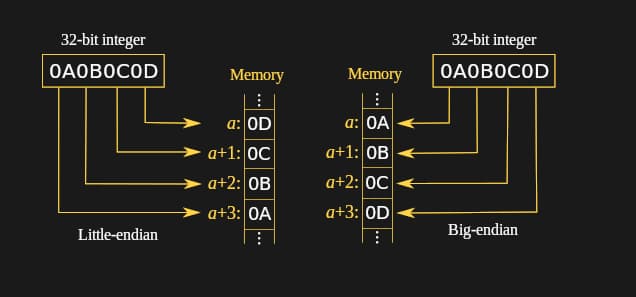
字节序(endianness)指的是在内存中排列字节的顺序。在大端序系统中,最高有效字节存储在最小的内存地址,而在小端序系统中,最低有效字节最先存储。理解字节序在套接字编程中至关重要,因为通过网络传输的数据可能需要在不同的字节序格式之间转换,以确保不同系统能够正确解释数据。这种转换确保了数据的一致性和准确性,无论通信设备的底层架构如何。
例如,一个 32 位值 1,200,000(十六进制 0x00124F80)展示了字节序。在大端序系统中,字节按 0x00 0x12 0x4F 0x80 从低地址到高地址存储。在小端序系统中,顺序相反:0x80 0x4F 0x12 0x00。
Endianness
(Order of bytes in memory)
Big-Endian System
+-----------------+-----------------+-----------------+------------------+
| Most Significant| | | Least Significant|
| Byte | | | Byte |
| (MSB) | | | (LSB) |
+-----------------+-----------------+-----------------+------------------+
| 0x00 | 0x12 | 0x4F | 0x80 |
+-----------------+-----------------+-----------------+------------------+
| Address: 0x00 | Address: 0x01 | Address: 0x02 | Address: 0x03 |
+-----------------+-----------------+-----------------+------------------+
Little-Endian System
+------------------+-----------------+-----------------+------------------+
| Least Significant| | | Most Significant |
| Byte | | | Byte |
| (LSB) | | | (MSB) |
+------------------+-----------------+-----------------+------------------+
| 0x80 | 0x4F | 0x12 | 0x00 |
+------------------+-----------------+-----------------+------------------+
| Address: 0x00 | Address: 0x01 | Address: 0x02 | Address: 0x03 |
+------------------+-----------------+-----------------+------------------+
假设你收到 0x00124F80,而你不知道它是大端序还是小端序。如果使用错误的字节序来解释这些字节,你将得到一个完全不同的值。在大端序格式中,最高有效字节在前,所以 0x00124F80 保持不变(十进制值:1,200,000)。然而,在小端序格式中,字节顺序反转,值变为 0x804F1200(十进制值:2,152,665,600)。这种差异可能导致数据处理中的重大错误,因此正确处理字节序非常重要。
为了用更简单的十进制例子说明字节序的概念,考虑 32 位值 574。在大端序系统中,最高有效数字先存储。对于 574,数字是 5、7 和 4。在大端序系统中,这将存储为 500(5 x 100)、70(7 x 10)和 4(4 x 1),按此顺序。相反,小端序系统将这些数字按相反顺序存储:4(4 x 1)、70(7 x 10)和 500(5 x 100)。这种反转可能导致数值被错误解释。
Network byte order
因此,机器在通信时对字节序达成一致是至关重要的,以确保数据被正确解释。例如,在互联网通信中,RFC 1700 和 RFC 9293 等标准定义了使用大端序格式,也称为网络字节序。这种标准化确保了网络上所有设备一致地解释数据,防止错误和误解。
RFC 1700: 互联网协议文档中使用十进制表示数字,并以“大端序”顺序描述数据…… RFC 9293: 源地址: 网络字节序中的 IPv4 源地址 目标地址: 网络字节序中的 IPv4 目标地址 https://datatracker.ietf.org/doc/html/rfc768 https://datatracker.ietf.org/doc/html/rfc1700
机器协议
如果应用程序定义了一个指定字节序的协议,发送方和接收方必须遵守该协议。如果协议规定数据中的某些字段应为网络字节序,则必须相应地转换这些字段。依赖纯文本的数据格式(如 JSON 和 XML)要么对字节序无依赖(将数据视为字节串),要么有自己的编码和解码多字节值的规范。
字节序只适用于多字节值,影响表示较大数据类型(如整数和浮点数)的字节序列的顺序。单字节值不受字节序的影响。
例如,在 Rust 中,crates bincode 和 postcard 默认使用小端序。这意味着,当你使用这些 crates 序列化数据时,多字节值将按小端序格式排序,除非另有规定。
绑定的套接字地址
如果你阅读或观看过任何关于套接字编程的内容,你几乎肯定会遇到一些C语言的示例。例如,你可能见过如下代码。这是因为,如前所述,IP地址和端口需要以大端序格式表示:
address.sin_family = AF_INET;
address.sin_addr.s_addr = htonl(...);
address.sin_port = htons(PORT);
bind(sockfd, (struct sockaddr *)&address, sizeof(struct address))
...
这些函数 htons 和 htonl 是一系列 C 辅助函数的一部分,帮助将多字节值转换为主机字节序。这些函数确保数据能被正确解释,不论底层系统的字节序如何。
The htonl() function converts the unsigned integer hostlong from host byte order to network byte order.
The htons() function converts the unsigned short integer hostshort from host byte order to network byte order.
The ntohl() function converts the unsigned integer netlong from network byte order to host byte order.
The ntohs() function converts the unsigned short integer netshort from network byte order to host byte order.
现代编程语言和框架通常会处理这些格式,并提供管理它们的专门函数。例如,在 Rust 中,我们可以这样创建地址:
let server_address = SockaddrIn::from_str("127.0.0.1:8080").expect("...");
在前一行中,由于实现原因,我们不必处理字节排序。但是,我们可以检查地址以确定机器上的默认字节顺序,在我的例子中是小端序。我们还可以根据 IP 地址和端口的需要将其转换为大端字节。
// Create a socket address
let sock_addr = SockaddrIn::from_str("127.0.0.1:6797").expect("...");
let sockaddr: sockaddr_in = sock_addr.into();
println!("sockaddr: {:?}", sockaddr);
println!("s_addr Default: {}", sockaddr.sin_addr.s_addr);
// big endian
println!("s_addr be: {:?}", sockaddr.sin_addr.s_addr.to_be());
// little endian
println!("s_addr le: {:?}", sockaddr.sin_addr.s_addr.to_le());
当我们运行这段代码, 我们会获得如下输出:
$ cargo run --bin addr
sockaddr: sockaddr_in { sin_len: 16, sin_family: 2, sin_port: 36122, sin_addr: in_addr { s_addr: 16777343 }, sin_zero: [0, 0, 0, 0, 0, 0, 0, 0] }
s_addr Default: 16777343
s_addr be: 2130706433
s_addr le: 16777343
正如我们所提到的,尽管 Rust 和其他现代编程语言在某些级别上处理字节排序并提供方便的抽象,但理解这些基本概念总是有价值的。
实际示例: 处理客户端-服务器通信中的端序
既然我们已经了解了字节排序,那么我们将创建一个简单的示例来说明到目前为止所涉及的内容。为此,我们将创建一个从套接字接收文件的简单程序。客户端首先发送文件的大小,然后发送文件的数据。请注意,这将是一个简单的实现,保持代码简单以说明这个概念。
服务器端
我们将重用上一篇文章中关于创建流类型和 INET 系列的套接字服务器的代码。我们将创建一个简单的函数来设置这个套接字服务器并返回文件描述符。这将帮助我们保持一个干净的实现,并在以后的所有示例中重用它。该函数名为 create_tcp_server_socket,它非常简单,如下所示:
pub fn create_tcp_server_socket(addr: &str) -> Result<OwnedFd, nix::Error> {
let socket_fd = socket(
nix::sys::socket::AddressFamily::Inet, // Socket family
nix::sys::socket::SockType::Stream, // Socket type
nix::sys::socket::SockFlag::empty(),
None,
)?;
// Create a socket address
let sock_addr = SockaddrIn::from_str(addr).expect("...");
// Bind the socket to the address
bind(socket_fd.as_raw_fd(), &sock_addr)?;
// Listen for incoming connections
let backlog = Backlog::new(1).expect("...");
listen(&socket_fd, backlog)?;
Ok(socket_fd)
}
现在我们可以使用该函数创建服务器套接字并接受传入的连接。
fn main() {
let socket_fd = create_tcp_server_socket("127.0.0.1:8000").expect("...");
// Accept incoming connections
let conn_fd = accept(socket_fd.as_raw_fd()).expect("...");
}
接下来,在接受连接之后,我们期望接收客户端将通过网络传输的文件的大小。我们希望接收一个 32 位的无符号整数,所以我们准备了一个 4 字节的缓冲区来接收这个大小。然后从套接字中读取数据并将数据放入缓冲区:
// Receive the size of the file
let mut size_buf = [0; 4];
recv(conn_fd, &mut size_buf, MsgFlags::empty()).expect("...");
let file_size = u32::from_ne_bytes(size_buf);
println!("File size: {}", file_size);
如果您注意到,我们在这里使用了 from_ne_bytes。这个函数假设字节是按照机器的本机端序排列的(ne stands for native endianness)。因此,我们期望该值使用与我们的机器相同的端序。
最后,我们将使用该大小创建一个内存缓冲区,以便通过连接接收文件的数据并打印读取的字节。如上所述,这是一个简单而基本的实现,只是为了说明情况:
// Receive the file data
let mut file_buf = vec![0; file_size as usize];
let bytes_read = recv(conn_fd, &mut file_buf, MsgFlags::empty()).expect("...");
println!("File data bytes read: {:?}", bytes_read);
完整代码:
use nix::sys::socket::{accept, recv, MsgFlags};
use socket_net::server::create_tcp_server_socket;
use std::os::fd::AsRawFd;
fn main() {
let socket_fd = create_tcp_server_socket("127.0.0.1:8000").expect("...");
// Accept incoming connections
let conn_fd = accept(socket_fd.as_raw_fd()).expect("...");
// Receive the size of the file
let mut size_buf = [0; 4];
recv(conn_fd, &mut size_buf, MsgFlags::empty()).expect("...");
let file_size = u32::from_ne_bytes(size_buf);
println!("File size: {}", file_size);
// Receive the file data
let mut file_buf = vec![0; file_size as usize];
let bytes_read = recv(conn_fd, &mut file_buf, MsgFlags::empty()).expect("...");
println!("File data bytes read: {:?}", bytes_read);
}
客户端
对于我们的客户端,逻辑同样非常简单,类似于我们之前使用的逻辑,但是添加了一些微妙的内容,例如在发送实际数据之前读取文件并发送其大小。
... socket creation and connection
// Read the file into a buffer
let buffer = std::fs::read("./src/data/data.txt").expect("Failed to read file");
// send the size of the file to the server
let size: u32 = buffer.len() as u32;
send( socket_fd.as_raw_fd(), &size.to_ne_bytes(), MsgFlags::empty()).expect("...");
// send the file to the server
send(socket_fd.as_raw_fd(), &buffer, MsgFlags::empty()).expect("...");
有两件事需要注意: 正如我们前面提到的,我们为文件大小创建了一个 u32,并且我们使用 to_ne_bytes 函数来发送按本地端序排列的字节,在我的例子中是 little-endian。
data.txt 文件是一个简单的文本文件,包含一些 lorem ipsum 数据。我们可以使用 stat 命令检查它的大小:
$ stat -c%s ./src/data/data.txt
574
如果你想知道为什么我们必须处理大小的端序,而不是文件内容本身,记住我们之前学到的: 许多依赖于纯文本的应用程序数据格式要么是字节顺序独立的(将数据作为字节字符串处理),要么…
运行
现在我们可以运行服务器和客户机来查看输出并了解其工作原理。文件的大小是 574 字节,我们发送整个文件。
# Server
$ cargo run --bin tcp-file-server
Socket file descriptor: 3
Socket bound to address: 127.0.0.1:8000
File size: 574
File data bytes read: 574
# Client
$ cargo run --bin tcp-file-client
Socket file descriptor: 3
Sending file size: 574
Sending file data
到目前为止,一切顺利,对吧? 行为如预期的那样: 我们正在发送一个 574 字节的文件,并且我们正在服务器中接收它。这是因为客户端和服务器都使用 ne (native endianness),而且由于它们在同一台机器上,它们都使用 little-endian。但是如果客户端使用不同的端序呢? 例如,如果它使用大端字节 big-endian 来发送大小呢?
我们可以通过修改客户端的这一行来模拟将要发生的事情,以指示它以大端字节而不是小端字节发送数据。为此,我们使用 to_be_bytes (be 代表大端字节):
send( socket_fd.as_raw_fd(), &size.to_be_bytes(), MsgFlags::empty()).expect("...");
如果我们再次运行程序,我们将看到为什么理解端序是重要的。从客户端的角度来看,我们发送的是相同的值,只是用了不同的端序。然而,如果你看看我们的服务器,你会注意到这个问题:
# Client
$ cargo run --bin tcp-file-client
Socket file descriptor: 3
Sending file size: 574
Sending file data
服务器仍然将大小视为以相同的端序来处理,即小端序。但它不再是小端式的;它是大端的。这将导致一个完全不同且不正确的值。在这个简单的例子中,它导致服务器分配的内存远远超过缓冲区接收文件所需的内存。可以想象,在更复杂的情况下,这个问题可能会产生更大、更严重的影响。
# Server
$ cargo run --bin tcp-file-server
Socket file descriptor: 3
Socket bound to address: 127.0.0.1:8000
File size: 1040318464
File data bytes read: 574
如果我们使用本地的操作系统位大小,比如 64 位整数,并在客户端和服务器中使用 u64 类型作为大小变量,那么问题可能会更糟。我们可以在客户端和服务器端修改以下几行,看看结果:
// server
let mut size_buf = [0; 8];
...
let file_size = u64::from_ne_bytes(size_buf);
// client
let size: u64 = buffer.len() as u64;
在做了这些修改之后,让我们再次运行服务器和客户端:
# Server
$ cargo run --bin tcp-file-server
Socket file descriptor: 3
Socket bound to address: 127.0.0.1:8000
File size: 4468133780304953344
memory allocation of 4468133780304953344 bytes failed
Aborted (core dumped)
在这种情况下,整数的多字节表示更大,并且在错误的字节顺序下,值表示变得巨大。在这里,服务器尝试分配大约 4.4 eb 的内存,这远远超过当前任何机器上的可用内存。这说明正确处理端序是多么重要,因为不正确的处理可能导致严重的问题,如内存分配失败和程序崩溃。 您可以在这个 repo 中找到这个示例和未来示例的代码。
总结
理解字节序对于开发健壮的网络应用至关重要。如示例所示,即使是简单的任务如通过网络发送文件,如果不正确处理字节序,也会导致严重问题。通过遵循标准并正确管理字节顺序,我们确保数据在不同系统间被准确解释,防止错误并提高应用的可靠性。现代编程语言如Rust提供了有用的抽象,但对这些基础概念的牢固掌握使开发人员能够更有效地排除故障和优化代码。在网络通信中处理多字节值时,务必注意字节序,以避免潜在的陷阱。
感谢你的阅读。这篇博客是我学习旅程的一部分,非常重视你的反馈。关于套接字和网络还有更多内容可供探索和分享,请关注即将发布的文章。希望我们能在这个领域共同学习和成长。编程愉快!
原文链接:https://www.kungfudev.com/blog/2024/06/14/network-sockets-endianness