Spark Structured Streaming 中的外连接
— 焉知非鱼以前,我们在 Apache Spark 中发现了流到流的内连接,但是它们不是唯一受支持的类型。另一个是外连接,使我们可以在不匹配行的情况下连接流。
这篇文章是关于结构化流模块中的外连接的。它的第一部分介绍了有关这种连接的一些理论观点。第二篇展示了如何通过一些 Scala 示例来实现它。
当匹配是可选的 #
流式外连接与经典的,类似批处理的连接没有什么不同。有了它们,我们总是从一侧获得所有行,即使其中一些行在连接数据集中没有匹配项也是如此。对于 RDBMS 之类的有限数据源,此类不匹配将直接返回,其中 null 表示另一侧的行。但是,无限来源的逻辑是不同的。由于不同的特性,例如网络延迟影响或脱机设备产生事件,因此在给定时刻我们可能没有所有连接的元素。因此,我们必须能够将物理连接推迟到我们确定要连接的大多数行都将到来的那一刻。为此,我们需要将一侧的行存储在某处。并且,如果您还记得 Apache Spark 结构化流中流之间的内连接的文章中的一些注释,则 Apache Spark 为此使用状态存储。下图从鸟瞰显示了这一点:
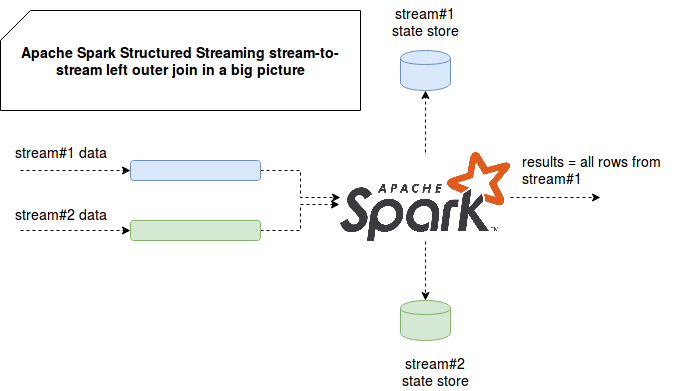
该图像清楚地表明,与内连接水位的情况一样,行被缓冲在状态存储中。 外连接还使用水位和范围查询条件的概念来确定何时不应在给定的行中接收第二个流中的任何新匹配。 这就是为什么完全没有水位的外连接是不可能的:
it should "fail without watermark and range condition on watermark in the query" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") ,
"leftOuter")
val exception = intercept[AnalysisException] {
stream.writeStream.trigger(Trigger.ProcessingTime(5000L)).foreach(RowProcessor).start()
}
exception.getMessage() should include("Stream-stream outer join between two streaming DataFrame/Datasets is not " +
"supported without a watermark in the join keys, or a watermark on the nullable side and an appropriate range condition")
}
it should "fail without watermark and only with range condition" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
expr("joinedEventTimeWatermark < mainEventTimeWatermark + interval 2 seconds"),
"leftOuter")
val exception = intercept[AnalysisException] {
stream.writeStream.trigger(Trigger.ProcessingTime(5000L)).foreach(RowProcessor).start()
}
exception.getMessage() should include("Stream-stream outer join between two streaming DataFrame/Datasets is not " +
"supported without a watermark in the join keys, or a watermark on the nullable side and an appropriate range condition")
}
水位和范围查询 #
现在让我们看看如果与上面不同,我们在列上定义水位会发生什么:
it should "emit rows before accepted watermark" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
mainEventsDataset("mainEventTimeWatermark") === joinedEventsDataset("joinedEventTimeWatermark"),
"leftOuter")
val query = stream.writeStream.foreach(RowProcessor).start()
while (!query.isActive) {}
new Thread(new Runnable() {
override def run(): Unit = {
val stateManagementHelper = new StateManagementHelper(mainEventsStream, joinedEventsStream)
var key = 0
val processingTimeFrom1970 = 10000L // 10 sec
stateManagementHelper.waitForWatermarkToChange(query, processingTimeFrom1970)
println("progress changed, got watermark" + query.lastProgress.eventTime.get("watermark"))
key = 2
// We send keys: 2, 3, 4, 5, 6 in late to see watermark applied
var startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query) - 5000L
while (query.isActive) {
if (key % 2 == 0) {
stateManagementHelper.sendPairedKeysWithSleep(s"key${key}", startingTime)
} else {
mainEventsStream.addData(MainEvent(s"key${key}", startingTime, new Timestamp(startingTime)))
}
startingTime += 1000L
key += 1
}
}
}).start()
query.awaitTermination(120000)
val groupedByKeys = TestedValuesContainer.values.filter(keyAndValue => keyAndValue.key != "key1")
.groupBy(testedValues => testedValues.key)
groupedByKeys.keys shouldNot contain allOf("key2", "key3", "key4", "key5", "key6")
val values = groupedByKeys.flatMap(keyAndValue => keyAndValue._2)
val firstRowWithoutMatch = values.find(joinResult => joinResult.joinedEventMillis.isEmpty)
firstRowWithoutMatch shouldBe defined
val firstRowWithMatch = values.find(joinResult => joinResult.joinedEventMillis.nonEmpty)
firstRowWithMatch shouldBe defined
values.foreach(joinResult => {
assertJoinResult(joinResult)
})
}
通过外连接,我们可能想知道返回了哪些结果-仅是有关水位的最新结果还是全部独立于水位的值? 以下测试显示连接结果是通过匹配来确定的。 也就是说,匹配的行将尽快返回,而未匹配的行仅在达到水位时间之后返回:
it should "prove the joined rows are emitted at every batch and not after watermark expiration" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark",
current_timestamp.as("generationTime"))
.withWatermark("mainEventTimeWatermark", "30 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "30 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
mainEventsDataset("mainEventTimeWatermark") === joinedEventsDataset("joinedEventTimeWatermark"),
"leftOuter")
val query = stream.writeStream.foreach(RowProcessor).start()
while (!query.isActive) {}
new Thread(new Runnable() {
override def run(): Unit = {
val stateManagementHelper = new StateManagementHelper(mainEventsStream, joinedEventsStream)
var key = 0
val processingTimeFrom1970 = 60000L // 60 sec
stateManagementHelper.waitForWatermarkToChange(query, processingTimeFrom1970)
println("progress changed, got watermark" + query.lastProgress.eventTime.get("watermark"))
key = 2
var startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query)
while (query.isActive) {
stateManagementHelper.sendPairedKeysWithSleep(s"key${key}", startingTime)
startingTime += 1000L
key += 1
}
}
}).start()
query.awaitTermination(120000)
val groupedByKeys = TestedValuesContainer.values.filter(joinResult => joinResult.key != "key1")
.groupBy(testedValues => testedValues.key)
val values = groupedByKeys.flatMap(keyAndValue => keyAndValue._2)
values.nonEmpty shouldBe true
values.foreach(joinResult => {
val diffProcessingEventTime = joinResult.processingTime - joinResult.rowCreationTime.get
// It clearly shows that matched rows are processed as soon as a match is found, with the next processing
// time window
(diffProcessingEventTime/1000 < 30) shouldBe true
})
}
编写外连接查询时要考虑的另一点是,当水位不是连接键时,这种连接将不起作用。 如果要检查一侧的水位大于还是小于另一侧的水位,则必须定义范围条件,如以下测试所示:
it should "fail if the watermark is not a join key and there is no range condition" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().repartition(1).select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().repartition(1).select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
expr("joinedEventTimeWatermark >= mainEventTimeWatermark"),
"leftOuter")
val exception = intercept[AnalysisException] {
stream.writeStream.trigger(Trigger.ProcessingTime(5000L)).foreach(RowProcessor).start()
}
exception.getMessage() should include("Stream-stream outer join between two streaming DataFrame/Datasets is not " +
"supported without a watermark in the join keys, or a watermark on the nullable side and an appropriate range condition")
}
it should "emit rows before accepted watermark with range condition" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().repartition(1).select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().repartition(1).select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
// Either equality criteria on watermark or not equality criteria on watermark with range conditions are required for outer joins
expr("joinedEventTimeWatermark >= mainEventTimeWatermark") &&
expr("joinedEventTimeWatermark < mainEventTimeWatermark + interval 4 seconds"),
"leftOuter")
val query = stream.writeStream.foreach(RowProcessor).start()
while (!query.isActive) {}
new Thread(new Runnable() {
override def run(): Unit = {
val stateManagementHelper = new StateManagementHelper(mainEventsStream, joinedEventsStream)
var key = 0
val processingTimeFrom1970 = 10000L // 10 sec
stateManagementHelper.waitForWatermarkToChange(query, processingTimeFrom1970)
println("progress changed, got watermark" + query.lastProgress.eventTime.get("watermark"))
// We send keys: 2, 3, 4, in late to see watermark applied
var startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query) - 4000L
stateManagementHelper.sendPairedKeysWithSleep(s"key2", startingTime)
stateManagementHelper.sendPairedKeysWithSleep(s"key3", startingTime + 1000)
stateManagementHelper.sendPairedKeysWithSleep(s"key4", startingTime + 2000)
key = 5
startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query) + 1000L
while (query.isActive) {
val keyName = s"key${key}"
val flushed = if (key % 4 == 0) {
// here we sent the events breaking range condition query
val joinedEventTime = startingTime + 6000
stateManagementHelper.collectAndSend(keyName, startingTime, Some(joinedEventTime), withJoinedEvent = true)
} else if (key % 3 == 0) {
// Here we send only main key
stateManagementHelper.collectAndSend(keyName, startingTime, None, withJoinedEvent = false)
} else {
// Here we sent an "in-time event"
stateManagementHelper.collectAndSend(keyName, startingTime, Some(startingTime+1000), withJoinedEvent = true)
}
if (key >= 12) {
startingTime += 1000L
}
key += 1
if (flushed) {
Thread.sleep(1000L)
}
}
}
}).start()
query.awaitTermination(120000)
val groupedByKeys = TestedValuesContainer.values.filter(joinResult => joinResult.key != "key1").
groupBy(testedValues => testedValues.key)
// Ensure that rows with event time before new watermark (00:00:08) were not processed
groupedByKeys.keys shouldNot contain allOf("key2", "key3", "key4")
// Some checks on values
val values = groupedByKeys.flatMap(keyAndValue => keyAndValue._2)
// For the joined rows violating range condition query we shouldn't see the event time of
// nullable side
val lateJoinEvents = values
.filter(joinResult => joinResult.key.substring(3).toInt % 4 == 0 && joinResult.joinedEventMillis.isEmpty)
lateJoinEvents.nonEmpty shouldBe true
// Here we check whether for the case of "only main keys" the rows are returned
val noMatchEvents = values
.find(joinResult => joinResult.key.substring(3).toInt % 3 == 0 && joinResult.joinedEventMillis.isEmpty)
noMatchEvents.nonEmpty shouldBe true
// Here we validate if some subset of fully joined rows were returned
val matchedEvents = values.find(joinResult => joinResult.joinedEventMillis.nonEmpty)
matchedEvents.nonEmpty shouldBe true
values.filter(joinResult => joinResult.joinedEventMillis.nonEmpty).foreach(joinResult => {
// joined row has always event time 1 second bigger than the main side's row
(joinResult.joinedEventMillis.get - joinResult.mainEventMillis) shouldEqual 1000L
})
}
显然,即使我们正在处理流,外连接也遵循与有限数据源相同的规则。 这意味着,如果我们在 ON 子句中具有非水位条件,它将自动丢弃所有事件-如果它们是否与另一侧的行匹配,则单独丢弃:
it should "return no rows because of mismatched condition on join query" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
mainEventsDataset("mainEventTimeWatermark") === joinedEventsDataset("joinedEventTimeWatermark") &&
// This condition invalidates every row
joinedEventsDataset("joinedEventTime") <= 0,
"leftOuter")
val query = stream.writeStream.trigger(Trigger.ProcessingTime(5000L)).foreach(RowProcessor).start()
while (!query.isActive) {}
new Thread(new Runnable() {
override def run(): Unit = {
val stateManagementHelper = new StateManagementHelper(mainEventsStream, joinedEventsStream)
var key = 0
val processingTimeFrom1970 = 10000L // 10 sec
stateManagementHelper.waitForWatermarkToChange(query, processingTimeFrom1970)
println("progress changed, got watermark" + query.lastProgress.eventTime.get("watermark"))
key = 2
// We send keys: 2, 3, 4, 5, 7 in late to see watermark applied
var startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query) - 5000L
while (query.isActive) {
if (key % 2 == 0) {
stateManagementHelper.sendPairedKeysWithSleep(s"key${key}", startingTime)
} else {
mainEventsStream.addData(MainEvent(s"key${key}", startingTime, new Timestamp(startingTime)))
}
startingTime += 1000L
key += 1
}
}
}).start()
query.awaitTermination(120000)
// As you can see, since the extra JOIN condition invalidates every output. For the ones without match on joined
// side it's normal since joinedEventTime is null. For the ones with matching it's also normal since the value
// of this column is never lower than 0.
TestedValuesContainer.values shouldBe empty
}
在本文中提供的所有示例中,我们可以了解有关 Apache Spark 结构化流中的流外连接的一些特定知识。 如第一节中简短描述的那样,它们使我们可以使用可能缺少连接值的流进行连接。 这是一个真实的用例,因为我们并不总是观察到对发射事件的反应(人为的,机械的…)。 但是,如代码片段所示,没有水位作为连接键或范围查询条件的情况下,外连接将无法工作。