six slices of pie
— 焉知非鱼第 15 周挑战赛的第一个任务是找到甜品的最佳排队位置。
这是对创造越野车鞭子或牛仔电影或实体书店或碳基能源的老难题的重新表述:什么时候才是选择在一个不断缩小的馅饼中获得一块不断增加的最佳时机?
在这个任务中,馅饼足够大,可以容纳100个人,但排在第一位的人只能得到相当于其中1%的一块。第二个人得到剩下的2%,第三个人得到之后剩下的3%,等等,等等,直到第一百个人得到前面99个人分到自己那份后剩下的100%的碎屑。换句话说,我们要"让苹果派再次伟大!"
实际的任务是确定哪一个是队伍中的最佳位置。是早早地进入,得到一小块还算大的馅饼呢?还是等待,最终获得一块更大的剩饼?让我们用六种不同的方式来回答这个问题。
必需的切片 #
我的开发者生涯是以C语言程序员的身份开始的,我仍然觉得以命令式模式来处理像这样的小问题是很自然的。所以,我第一次尝试回答这个问题(幸好是用 Raku 而不是C语言)的时候是这样的。
# Start with a full pie, and no idea who gets the most...
my $pie = 1.00; # i.e. 100%
my $max-share = 0.00; # i.e. 0%
my $max-index;
# For everyone in line...
for 1..100 -> $N {
# Take N% of what’s left as the next share...
my $share = $pie * $N/100;
$pie -= $share;
# Remember it if it’s maximal...
if $share > $max-share {
($max-index, $max-share) = ($N, $share);
}
}
# Report the biggest share taken...
say "$max-index => $max-share";
它不漂亮,也不简洁,也不简单,但它很快,而且它能产生一个答案:
10 => 0.06281565095552947
换句话说,最理想的排位是第十位,这样可以保证你获得超过 6¼% 的原始派。
但是这个解决方案有一些问题….不只是那些明显的问题,如笨拙,繁琐,和太多的移动部件。更深层次的问题是,它做出了一个重大的无理假设(这个假设恰好是正确的,虽然这不是借口,因为我当时并不知道)。
所以,让我们着手改进解决方案。
我所做的无理假设是,实际上队列中只有一个可选的位置。但如果有两个同样好的位置呢?或者三个呢?或者是一个高原之后,所有的地方都一样好呢?上面的代码其实只告诉我们,排在第十位的人是第一个获得最大份额的人。如果还有其他人呢?
这也是一个危险的信号,我们是在"手动"识别第一个最大值,通过在循环内创建每个新的份额时检查它。Raku 有一个非常好的内置 max 函数,可以为我们做到这一点。当然,我们真正需要的是一个能够返回所有找到最大值的地方的 max 函数,而不仅仅是第一个。嗯…Raku 也有:maxpairs。
然而,代码中的另一个危险信号是需要添加注释,记录代表百分比的各种数字。(例如 1.00 和 $N/100)。应该有一种方法可以让代码本身明显地体现这一点。
这是我的第二次尝试,结合了所有这些改进,提出了一个必要的解决方案:
# Add a percentage operator...
sub postfix:<%> (Numeric $x) { $x / 100 }
# Start with 100% of the pie, and no shares yet...
my $pie = 100%;
my %share;
# For everyone in line...
for 1..100 -> $N {
# Remove a share for the Nth person from the pie...
$pie -= ( %share{$N} = $pie * $N% );
}
# Finally, report the share(s) with maximal values...
say %share.maxpairs;
令人惊讶的是,Raku 并没有内置"百分比"运算符。好吧,也许这并不奇怪,因为它已经使用 % 符号作为前缀符号、中缀运算符、中缀 regex 元运算符和一个无名静态变量。在这个单一字符上增加一个永久性的第五种含义,可能不会大大改善整体代码的清晰度。
只不过,在这里,它绝对是这样的。这也是为什么 Raku 让添加后缀 % 运算符变得简单易行的原因,这个运算符只需将其数值参数除以100即可:
sub postfix:<%> (Numeric $x) { $x / 100 }
所以现在我们可以写:
$pie = 100%
和
%share{$N} = $pie * $N%
而不需要注释来解释它们是百分比。
因为我们将每个计算出的份额都存储在哈希表中,所以我们可以使用内置的 .maxpairs 方法来检索 %share 中所有具有最大值的条目列表。打印出这个列表,我们发现它只包含一对:
(10 => 0.06281565095552947)
…从而证实,排在第十位的人是唯一一个实现最优派的人。
有状态的饼 #
第二个版本缩短了 33%,可能可读性也提高了 33%,但还是有一些问题。例如,任何时候我看到一个像 %shares 这样的变量,它的存在只是为了在 for 循环中被填充,然后在之后精确地使用一次,我就会感到不安。然后,我就想到了 gather/take:
say maxpairs gather for 1..100 -> $N {
state $pie = 100%;
$pie -= my $share = $pie * $N%;
take $N => $share;
}
在这个版本中,我们把 $pie 变量移到了循环里面,声明它是一个(持久)状态变量,而不是一个(瞬时)my 变量。我们仍然在每次迭代时计算剩余饼的 N%,但现在我们将该值与 N 的当前值作为一对: take $N => $share。
这意味着,循环终止后,gather 将返回一个对儿(pair)的列表,其键是行中的位置,其值是饼中各自的份额。
一旦循环终止,gather 返回对儿(pair)的列表,我们只需要过滤出最大的份额。令人惊讶的是,Raku 并没有提供一个合适的 maxpairs 内置函数(只有哈希上的 .maxpairs 方法),但幸运的是,Raku 可以很容易地构建一个非常强大的函数,它将处理我们在本探索的其余部分中要扔给它的一切:
# Maximal values from a list of pairs...
multi maxpairs (@list where @list.all ~~ Pair, :&by = {$_}) {
my $max = max my @values = @list».value.map: &by;
@list[ @values.pairs.map: {.key unless .value cmp $max} ];
}
# Maximal values extracted from a list of containers...
constant Container = Iterable | Associative;
multi maxpairs (@list where @list.all ~~ Container, :&by!) {
my $max = max my @values = @list.map: &by;
@list[ @values.pairs.map: {.key unless .value cmp $max} ] :p;
}
# Maximal values directly from a list of anything else...
multi maxpairs (:&by = {$_}, *@list) {
my $max = max my @values = @list.map: &by;
@list[ @values.pairs.map: {.key unless .value cmp $max} ] :p;
}
这个函数有三个乘法分派的版本,因为我们需要以稍微不同的方式处理各种类型的列表。尽管如此,在每一种情况下,我们首先提取我们将要最大化的实际值(my @values = @list.map: &by),然后找到这些值的最大值(my $max = max my @values),然后我们找到具有该最大值的每个列表元素的索引(.key unless .value cmp $max),最后返回这些索引处的元素,作为一个对儿的列表(@list[...] :p)。
有了这个函数的"内置",我们可以立即识别并打印循环中收集到的每一个最大对儿的列表:say maxpairs gather for 1...100 {...}。
序列饼 #
每当我意识到我在 Raku 中使用 gather 来生成一个值的序列时,我就会马上想,我是否可以用 …序列生成操作符来更容易地完成这个操作。这个操作符特别适合于从以前的值建立新的值,这正是我们在这里所做的:当我们逐步增加我们发放的百分比时,逐步减少饼。
... 操作符有三个组成部分:一个初始值,一些用于从前一个值建立下一个值的代码,以及一个终止条件。在本例中,我们的初始条件只是我们有一个完整的馅饼,还没有人分到馅饼。
hash( pie => 100%, N => 0, share => 0% )
要想从之前的数值中建立一个新的数值,我们只需将 N 递增,然后建立一个新的哈希,在这个哈希中,N 被赋予其更新的数值,分配一个新的份额 N%,而饼本身也会被这个份额减少(通过将其减少到 (100-N)%)。也就是:
sub next-share (\previous) {
given previous<N> + 1 -> \N {
return hash
N => N,
share => previous<pie> * N%
pie => previous<pie> * (100 - N)%,
}
}
然后我们就可以建立我们的 shares 列表:
constant shares
= hash(pie=>100%, N=>0, share=>0%), &next-share ... *;
请注意,我们的终止条件是 *(“管他呢,老兄!"),所以这实际上是一个被惰性计算的无限列表。但我们只对前101个值感兴趣(即从 N=>0 到 N=>100),所以我们提取这些值,然后找到最大的对,使用每个元素的份额值来比较它们。
say maxpairs :by{.<share>}, shares[^100];
请注意,我们现在已经从最初的迭代解决方案中走了多远。这种方法或多或少只是描述了我们想要的东西。我们简单地陈述初始条件,并描述数值如何变化。然后我们要求提供我们所需要的具体信息。显示出前100份中按份额排序的最大对数
两种解决方案需要的代码量差不多,但这个解决方案包含算法错误、计算错误或逐个出问题的可能性要小得多。它甚至不需要任何变量就能完成工作。
函数式派 #
而说到不需要任何变量,那纯函数式的解决方案呢?
嗯,这也很简单。我们只需要使用经典的递归列表生成模式:
To return a list of shares of the remaining pie...
With the next share (i.e. N% of what’s left)...
Return that share and its position in the list
Plus the list of shares of the remaining pie
(Provided there’s still any pie left to share)
这句话,逐行翻译成 Raku,看起来是这样的:
sub shares (\pie = 100%, \N = 1) {
given N% * pie -> \share {
pair(N, share),
|shares( pie - share, N+1)
if 1% <= share <= 100%
}
}
或者,如果你喜欢你的递归和基准情形最好区分开来:
# Recursive definition of shares list...
multi shares (\pie = 100%, \N = 1) {
given pie * N% -> \share {
pair(N, share), |shares(pie - share, N+1)
}
}
# Base case returns an empty list...
multi shares (\pie, \N where N > 100) { Empty }
无论哪种方式,一旦我们生成了完整的份额列表,我们只需要从该列表中提取最大的对儿:
say maxpairs shares();
数学派 #
在我完成那一连串的代码演变后的几天,有一天早上醒来,我懊恼地意识到我错过了一个"非常明显"的解决方案。
我想到了分配给每个排队的人的百分比模式;它们是如何线性增加的。
1%, 2%, 3%, 4%, ...
然后我想了想,任何时候还有多少馅饼,它不是线性减少的,而是指数减少的(因为每拿一份都会减少 N% 剩下的馅饼,而不是原来馅饼的 N%)。
100%, 100%×99%, 100%×99%×98%, 100%×99%×98%×97%, ...
如果我有这两份完整的名单(连续分红比例和累进派遗),那么我只需将每一个对应的元素相乘,就可以计算出每个排队的人将获得多少派:
1%, 2%, 3%, 4%, ...
× × × ×
100%, 100%×99%, 100%×99%×98%, 100%×99%×98%×97%, ...
在 Raku 中,创建一个线性增长的百分比列表是微不足道的:
(1%, 2% ... 100%)
而建立一个成倍减少的剩菜清单,几乎没有任何难度。
[\*] (100%, 99% ... 1%)
[\*] 运算符产生了一个百分比列表中元素连续相乘的部分乘积列表。换句话说,它先乘以前两个元素,然后乘以前三个元素,再乘以前四个元素,依此类推,直到产生一个所有部分乘积的列表。所以我们得到:
100%, (100% * 99%), (100% * 99% * 98%) ...
给定这两个列表,我们可以简单地将每个百分比乘以每个相应的剩菜量,使用向量乘法:
(1%, 2% ... 100%) »*« [\*] (100%, 99% ... 1%)
…给我们一个谁得到了多少馅饼的列表。然后我们就可以筛选出最大的指数/馅饼份额对:
say maxpairs (1%, 2%...100%) »*« [\*] (100%, 99%...1%);
我们的答案又来了……现在只有一行。
视觉饼 #
当然,每一个解决方案都有赖于我们有那个非常方便的 maxpairs 函数,在结果中搜索并定位行中的可选位置。
如果我们没有这个功能,或者其他任何"找到最大值"的函数,我们仍然可以眼看着答案,只要我们能看到数据是什么样子。
好吧,这在 Raku 中也很容易,这要感谢 Moritz Lenz 创建的一对可爱的模块:
use SVG;
use SVG::Plot;
# Work out the shares, as before...
constant shares = (1%, 2% ... 100%) »*« [\*] (100%, 99% ... 1%);
# Plot the data and write it to an SVG file...
spurt 'chart.svg'.IO,
SVG.serialize:
SVG::Plot.new(
title => 'Percentage shares of the pie',
values => [shares »*» 100,],
x => [0..100],
).plot(:xy-lines);
# Take a look...
shell 'open chart.svg';
…生成并显示如下图所示:
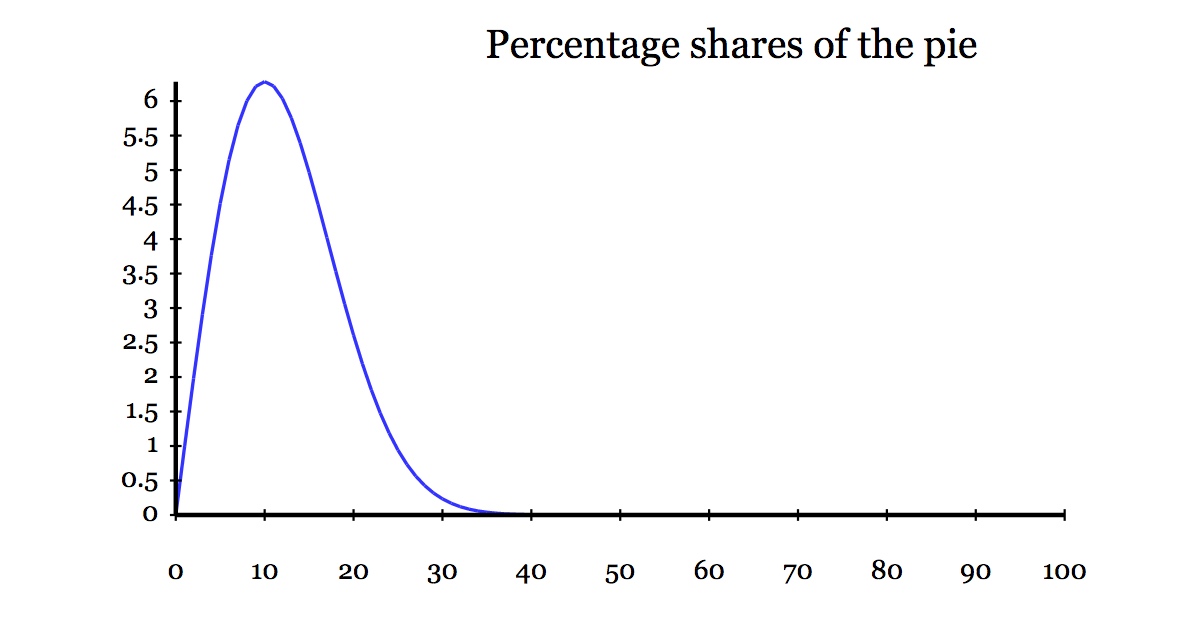
…一眼就能看出,第10号位仍然得到了最好的待遇,只得到了超过 6% 的馅饼。
所以,无论你是喜欢用命令式、状态式、声明式、函数式、数学式还是视觉式的方式来切饼,Raku 都能让你轻松地写出以你最舒服的方式思考的代码。
这一点很重要…不管是像让你无缝地添加像 % 或 maxpairs 这样的内建函数这样简单的东西,还是像生成复杂序列然后在它们之间应用向量运算这样方便的东西,或者是像允许你用任何一种编程范式流畅地编写代码这样深刻的东西,都能帮助你最有效地推理问题。
因为人们不应该适应编程语言的需求。编程语言应该适应人们的需求。
by Damian