Spark Structured Streaming 中的初始化状态
— 焉知非鱼不久前,Sunil 询问我是否可以像基于 DStream 的 API 一样在 Apache Spark 结构化流中加载初始状态。 由于回应并不明显,因此我决定调查并通过这篇文章分享调查结果。
文章首先简短地回忆了 Apache Spark Streaming 模块中的状态初始化。 下一节将讨论可用于在 Apache Spark 结构化流库中执行相同操作的方法。
流中的初始化状态 #
在基于 DStream 的库中初始化状态很简单。 您只需要创建一个基于键的 RDD 并将其传递给 StateSpec 的 initialState 方法:
"streaming processing" should "start with initialized state" in {
val conf = new SparkConf().setAppName("DStream initialState test").setMaster("local[*]")
val streamingContext = new StreamingContext(conf, Durations.seconds(1))
streamingContext.checkpoint("/tmp/spark-initialstate-test")
val dataQueue = new mutable.Queue[RDD[OneVisit]]()
// A mapping function that maintains an integer state and return a UserVisit
def mappingFunction(key: String, value: Option[OneVisit], state: State[UserVisit]): Option[(String, String)] = {
var visitedPages = state.getOption().map(userVisitState => userVisitState.visitedPages)
.getOrElse(Seq.empty)
value.map(visit => visit.page).foreach(page => visitedPages = visitedPages :+ page)
state.update(UserVisit(key, visitedPages))
Some((key, visitedPages.mkString(", ")))
}
val initialStateRdd = streamingContext.sparkContext.parallelize(Seq(
UserVisit("a", Seq("page1", "page2", "page3")),
UserVisit("b", Seq("page4")),
UserVisit("c", Seq.empty)
)).map(visitState => (visitState.userId, visitState))
val visits = Seq(
OneVisit("a", "page4"), OneVisit("b", "page5"), OneVisit("b", "page6"),
OneVisit("a", "page7")
)
visits.foreach(visit => dataQueue += streamingContext.sparkContext.makeRDD(Seq(visit)))
val stateSpec = StateSpec.function(mappingFunction _)
.initialState(initialStateRdd)
InMemoryKeyedStore.allValues.clear()
streamingContext.queueStream(dataQueue)
.map(visit => (visit.userId, visit))
.mapWithState(stateSpec)
.foreachRDD(rdd => {
rdd.collect().foreach {
case Some((userId, pages)) => InMemoryKeyedStore.addValue(userId, pages)
}
})
streamingContext.start()
streamingContext.awaitTerminationOrTimeout(10000)
InMemoryKeyedStore.getValues("a") should have size 2
InMemoryKeyedStore.getValues("a") should contain allOf("page1, page2, page3, page4", "page1, page2, page3, page4, page7")
InMemoryKeyedStore.getValues("b") should have size 2
InMemoryKeyedStore.getValues("b") should contain allOf("page4, page5", "page4, page5, page6")
}
在后台,DStream 有状态操作在 MapWithStateRDD 上运行,并且初始状态在状态计算中仅被视为输入 RDD:
/** Method that generates an RDD for the given time */
override def compute(validTime: Time): Option[RDD[MapWithStateRDDRecord[K, S, E]]] = {
// Get the previous state or create a new empty state RDD
val prevStateRDD = getOrCompute(validTime - slideDuration) match {
case Some(rdd) =>
if (rdd.partitioner != Some(partitioner)) {
// If the RDD is not partitioned the right way, let us repartition it using the
// partition index as the key. This is to ensure that state RDD is always partitioned
// before creating another state RDD using it
MapWithStateRDD.createFromRDD[K, V, S, E](
rdd.flatMap { _.stateMap.getAll() }, partitioner, validTime)
} else {
rdd
}
case None =>
MapWithStateRDD.createFromPairRDD[K, V, S, E](
spec.getInitialStateRDD().getOrElse(new EmptyRDD[(K, S)](ssc.sparkContext)),
partitioner,
validTime
)
}
结构化流中的初始化状态-流的静态连接 #
我最初想到的是面向 API 的结构化流中的初始化状态。 但是不幸的是,我没有找到任何引导计算状态的方法。 因此,我首先尝试通过组合数据集来实现状态管理。 第一个工作版本使用流的静态左连接:
private val MappingFunctionJoin: (Long, Iterator[Row], GroupState[Seq[String]]) => Seq[String] = (key, values, state) => {
val materializedValues = values.toSeq
val defaultState = materializedValues.headOption.map(row => Seq(row.getAs[String]("state_name"))).getOrElse(Seq.empty)
val stateNames = state.getOption.getOrElse(defaultState)
val stateNewNames = stateNames ++ materializedValues.map(row => row.getAs[String]("name"))
state.update(stateNewNames)
stateNewNames
}
"the state" should "be initialized with a join" in {
val stateDataset = Seq((1L, "old_page1"), (2L, "old_page2")).toDF("state_id", "state_name")
val testKey = "state-load-join"
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
inputStream.addData((1L, "page1"), (2L, "page2"))
val initialDataset = inputStream.toDS().toDF("id", "name")
val joinedDataset = initialDataset.join(stateDataset, $"id" === $"state_id", "left")
val query = joinedDataset.groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunctionJoin)
.writeStream
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(", ")))
.start()
query.awaitTermination(60000)
InMemoryKeyedStore.getValues(testKey) should have size 2
InMemoryKeyedStore.getValues(testKey) should contain allOf("old_page2, page2", "old_page1, page1")
}
即使它按预期工作,我也不满意。首先,映射函数变得更加复杂。它不再是简单的状态累积函数,因为它也需要管理状态初始化。同样,该解决方案需要始终将静态数据集保留在内存中,即使不需要初始状态也是如此。由于这两个缺点,我转向了使用基于状态检查点的另一种方法。
在结构化流中初始化状态-检查点 #
在结构化流中,您可以定义一个 checkpointLocation 选项,以提高数据处理的容错能力。定义检查点目录后,引擎将在重新开始处理之前首先检查是否有一些数据要还原。在要还原的数据中,您会发现在上一次执行期间累积的状态。
这个想法是或多或少地将可能存储在某些 NoSQL 或关系存储中的初始状态转换为流处理所使用的检查点状态:
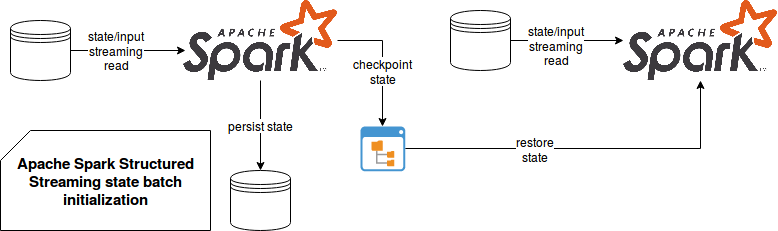
除了状态之外,检查点还存储有关数据源的信息。而且,由于用于状态初始化和流处理的源可能会有所不同,因此将它们混合在一起非常危险,就像您稍后将看到的那样,它将无法正常工作。另一方面,根据文档,状态操作具有更灵活的语义:“不允许对用户定义状态的模式进行任何更改,也不允许超时类型。用户定义状态映射函数内的任何更改均被允许,但更改的语义效果取决于用户定义的逻辑。”
正如我之前提到的,当数据源在初始化和实际处理步骤中相同时,此解决方案(或者说是魔改)可以正常工作。对于不兼容的源,要实现它要困难得多。因此,即使该魔改看上去与 DStream 的初始状态非常相似,但由于具有检查点语义,因此不建议这样做。除非您确定具有相同的数据源,并且偶然地在整个查询运行中保持一致。您可以在说明兼容性和不兼容性的以下测试案例中观察到这两点:
private val MappingFunction: (Long, Iterator[Row], GroupState[Seq[String]]) => Seq[String] = (_, values, state) => {
val stateNames = state.getOption.getOrElse(Seq.empty)
val stateNewNames = stateNames ++ values.map(row => row.getAs[String]("name"))
state.update(stateNewNames)
stateNewNames
}
"the state" should "be initialized for the same data source" in {
val testKey = "state-init-same-source-mode"
val checkpointDir = s"/tmp/batch-checkpoint${System.currentTimeMillis()}"
val schema = StructType(
Seq(StructField("id", DataTypes.LongType, false), StructField("name", DataTypes.StringType, false))
)
val sourceDir = "/tmp/batch-state-init"
val stateDataset = Seq((1L, "old_page1"), (2L, "old_page2")).toDF("id", "name")
stateDataset.write.mode(SaveMode.Overwrite).json(sourceDir)
val stateQuery = sparkSession.readStream
.schema(schema)
.json(sourceDir).groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunction)
.writeStream
.option("checkpointLocation", checkpointDir)
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(",")))
.start()
stateQuery.awaitTermination(45000)
stateQuery.stop()
val newInputData = Seq((1L, "page1"), (2L, "page2")).toDF("id", "name")
newInputData.write.mode(SaveMode.Overwrite).json(sourceDir)
val fileBasedQuery = sparkSession.readStream
.schema(schema)
.json(sourceDir).groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunction)
.writeStream
.option("checkpointLocation", checkpointDir)
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(", ")))
.start()
fileBasedQuery.awaitTermination(45000)
fileBasedQuery.stop()
InMemoryKeyedStore.getValues(testKey) should have size 4
InMemoryKeyedStore.getValues(testKey) should contain allOf("old_page2", "old_page1",
"old_page2, page2", "old_page1, page1" )
}
"the state" should "not be initialized for different data sources" in {
val testKey = "state-init-different-source-mode"
val checkpointDir = s"/tmp/batch-checkpoint${System.currentTimeMillis()}"
val schema = StructType(
Seq(StructField("id", DataTypes.LongType, false), StructField("name", DataTypes.StringType, false))
)
val sourceDir = "/tmp/batch-state-init"
val stateDataset = Seq((1L, "old_page1"), (2L, "old_page2")).toDF("id", "name")
stateDataset.write.mode(SaveMode.Overwrite).json(sourceDir)
val stateQuery = sparkSession.readStream
.schema(schema)
.json(sourceDir).groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunction)
.writeStream
.option("checkpointLocation", checkpointDir)
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(",")))
.start()
stateQuery.awaitTermination(45000)
stateQuery.stop()
// Cleans the checkpoint location and keeps only the state files
cleanCheckpointLocation(checkpointDir)
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
val inputDataset = inputStream.toDS().toDF("id", "name")
inputStream.addData((1L, "page1"), (2L, "page2"))
val mappedValues = inputDataset
.groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunction)
val query = mappedValues.writeStream.outputMode("update")
.option("checkpointLocation", checkpointDir)
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(","))).start()
query.awaitTermination(60000)
InMemoryKeyedStore.getValues(testKey) should have size 4
InMemoryKeyedStore.getValues(testKey) should contain allOf("old_page2", "old_page1", "page2", "page1")
}
private def cleanCheckpointLocation(checkpointDir: String): Unit = {
FileUtils.deleteDirectory(new File(s"${checkpointDir}/commits"))
FileUtils.deleteDirectory(new File(s"${checkpointDir}/offsets"))
FileUtils.deleteDirectory(new File(s"${checkpointDir}/sources"))
new File(s"${checkpointDir}/metadata").delete()
}
在结构化流中初始化状态-直接查找 #
在检查点尝试失败之后,我决定转向一个更简单的解决方案。 上一节中定义的映射函数会为第一次看到的每个键创建一个空序列。 但是,我们可以从另一个角度解决问题,仅在需要时才加载它,而不是在批处理中加载整个状态。 当然,当初始状态包含一些我们想要输出的信息时,即使没有关于它的新数据,也不适合这种情况。 但是至少该解决方案比魔改检查点系统的解决方案干净得多。
新的映射函数类似于以下代码片段。 它不返回空序列,而是在某些键值存储或任何其他保证O(1)查找的存储中查找数据:
private val MappingFunctionKeyValueLoad: (Long, Iterator[Row], GroupState[Seq[String]]) => Seq[String] = (key, values, state) => {
val stateNames = state.getOption.getOrElse(KeyValueStore.State(key))
val stateNewNames = stateNames ++ values.map(row => row.getAs[String]("name"))
state.update(stateNewNames)
stateNewNames
}
"the state" should "be loaded with key-value store" in {
val testKey = "state-load-key-value"
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
inputStream.addData((1L, "page1"), (2L, "page2"), (1L, "page3"))
val initialDataset = inputStream.toDS().toDF("id", "name")
val query = initialDataset.groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunctionKeyValueLoad)
.writeStream
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(", ")))
.start()
query.awaitTermination(60000)
InMemoryKeyedStore.getValues(testKey) should have size 2
InMemoryKeyedStore.getValues(testKey) should contain allOf("old_page1, page2",
"old_page1, old_page2, page1, page3")
}
在迭代的解决方案中,这似乎是最简单的。与基于 JOIN 的方法不同,它不再需要时不再保留数据。而且,它不会尝试破解结构化流库的语义,就像使用检查点的建议一样。另一方面,可能需要一些额外的预处理步骤才能将数据放入键值存储中。另外,它不会生成没有任何新传入数据的记录,因此对于某些必须完全恢复状态的管道可能是不可接受的。
在需要数据重新处理的所有情况下,初始化状态可能非常有用。例如,如果您对某个 Kafka 主题进行了有状态的处理,并且必须切换数据源,例如,使用另一个流代理系统中的数据,那么使用当前的实现可能会很困难。如文档中所述,“由于结果不可预测,通常不允许更改订阅的主题/文件”。如果没有简单的方法来移动状态,那么将很难实现这种情况。当然,您可以使用所描述的方法之一,但是与 DStream 的 initialState 之类的内置解决方案相比,它们更像是魔改。