Spark Structured Streaming 和 Kafka 偏移量管理
— 焉知非鱼前段时间,我对 Apache Spark 结构化流中 Apache Kafka 连接器的实现提出了3个有趣的问题。 我将在这篇文章中回答他们。
您可以想象,该帖子分为3个部分。 每个人都会回答一个问题。 在文章结尾,您应该更好地了解谁负责 Apache Kafka 连接器中的内容。
问题1:偏移量跟踪 #
第一个问题是关于 Apache Kafka 偏移量跟踪的。 谁跟踪他们,driver 或 executor? 在深入探讨该问题之前,让我们回顾一下我在分析结构化流式 Kafka 集成-Kafka源帖子中介绍的一些基础知识。 Apache Kafka 源代码首先从 driver 读取要处理的偏移量,然后将其分配给 executor 以进行实际处理。 因此,我们可以推断出,从这个角度来看,偏移量是由 driver 跟踪的。 您会注意到在 KafkaSource 类内部创建 KafkaSourceRDD 的代码中:
// Calculate offset ranges
val offsetRanges = topicPartitions.map { tp =>
// ...
}
// Create an RDD that reads from Kafka and get the (key, value) pair as byte arrays.
val rdd = new KafkaSourceRDD(
sc, executorKafkaParams, offsetRanges, pollTimeoutMs, failOnDataLoss,
但是,如果您对代码进行更深入的研究,尤其是在分区读取器上进行微批和连续执行时,您会发现它们也在跟踪偏移量:
// KafkaMicroBatchInputPartitionReader
override def next(): Boolean = {
if (nextOffset < rangeToRead.untilOffset) {
val record = consumer.get(nextOffset, rangeToRead.untilOffset, pollTimeoutMs, failOnDataLoss)
if (record != null) {
nextRow = converter.toUnsafeRow(record)
nextOffset = record.offset + 1
true
} else {
false
}
} else {
false
}
}
// KafkaContinuousInputPartitionReader
override def next(): Boolean = {
var r: ConsumerRecord[Array[Byte], Array[Byte]] = null
while (r == null) {
if (TaskContext.get().isInterrupted() || TaskContext.get().isCompleted()) return false
// Our consumer.get is not interruptible, so we have to set a low poll timeout, leaving
// interrupt points to end the query rather than waiting for new data that might never come.
try {
r = consumer.get(
nextKafkaOffset,
untilOffset = Long.MaxValue,
pollTimeoutMs,
failOnDataLoss)
} catch {
// We didn't read within the timeout. We're supposed to block indefinitely for new data, so
// swallow and ignore this.
case _: TimeoutException | _: org.apache.kafka.common.errors.TimeoutException =>
// This is a failOnDataLoss exception. Retry if nextKafkaOffset is within the data range,
// or if it's the endpoint of the data range (i.e. the "true" next offset).
case e: IllegalStateException if e.getCause.isInstanceOf[OffsetOutOfRangeException] =>
val range = consumer.getAvailableOffsetRange()
if (range.latest >= nextKafkaOffset && range.earliest <= nextKafkaOffset) {
// retry
} else {
throw e
}
}
}
nextKafkaOffset = r.offset + 1
currentRecord = r
true
}
executor 跟踪还有另一个作用。 他们只是在跟踪偏移量,以便与 driver 的偏移量保持同步。 您可以在带有范围对象的 if 条件中很好地看到这一点。 换句话说,executor 的 Kafka 使用者将读取记录,只要下一个预期的偏移量不大于 driver 发送的最终偏移量即可。
问题2:偏移量提交 #
很好,当我们已经知道谁负责偏移量跟踪时,就该回答有关谁提交偏移量,driver 或 executor的问题了。 如何在每个微批处理中解决偏移量的 driver 如何知道真正消费了什么? executor 可以自动提交偏移量吗?
这个问题的答案不像前一个那么明显。 为了找到它,我在源代码的 org/apache/spark/sql/kafka010 目录内的"ENABLE_AUTO_COMMIT_CONFIG"属性上做了一个小小的 grep 并得到了:
def kafkaParamsForDriver(specifiedKafkaParams: Map[String, String]): ju.Map[String, Object] =
ConfigUpdater("source", specifiedKafkaParams)
.set(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, deserClassName)
.set(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deserClassName)
// So that consumers in the driver does not commit offsets unnecessarily
.set(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false")
}
def kafkaParamsForExecutors(
specifiedKafkaParams: Map[String, String],
uniqueGroupId: String): ju.Map[String, Object] =
ConfigUpdater("executor", specifiedKafkaParams)
// So that consumers in executors does not commit offsets unnecessarily
.set(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false")
}
这是否意味着它们都不提交偏移量?在分析剩余的类之后,尤其是对 KafkaContinuousReader 和 KafkaMicroBatchReader的commit(end: Offset) 方法的实现,我产生了这种印象。在 MicroBatchExecution 中成功执行批处理结束时或在 ContiuousExecution 中成功执行纪元执行结束时调用 commit 方法。根据文档,该方法应实现为“通知源, Spark 已经完成了所有数据的偏移量小于或等于 end 的处理,并且将来只会请求大于 end 的偏移量。” 对于 Apache Kafka 源,两个实现都是空的,因此这是 driver 和 executor 使用者不提交任何偏移量的另一证明。
您还可以在 enable.auto.commit 属性旁边的文档中找到该说明,其中指出“Kafka 源不提交任何偏移量”。
问题3:偏移量检查点 #
最后一个未解决的问题是偏移量检查点。在上一部分之后,您了解了检查点有助于跟踪消费的偏移量。谁来检查他们,driver 或 executor?答案是 driver。分布式检查点将很难实现,而使用像 driver 这样的集中性参与者的检查点要容易得多。尤其是当他精心策划抵消偏移量检索时。
在内部,检查点偏移量由 StreamExecution 的 offsetLog 字段表示。并且,如果您对物理上保留偏移量的方法感兴趣,则应搜索 HDFSMetadataLog 的add(batchId: Long, metadata: T) 的声明。在处理下一个微批处理之前或在以连续模式处理纪元之后提交偏移量(想了解更多信息?您可以在 Apache Spark 结构化流中检查我的文章“连续执行”)。
综上所述,下图中将回顾所有3个答案:
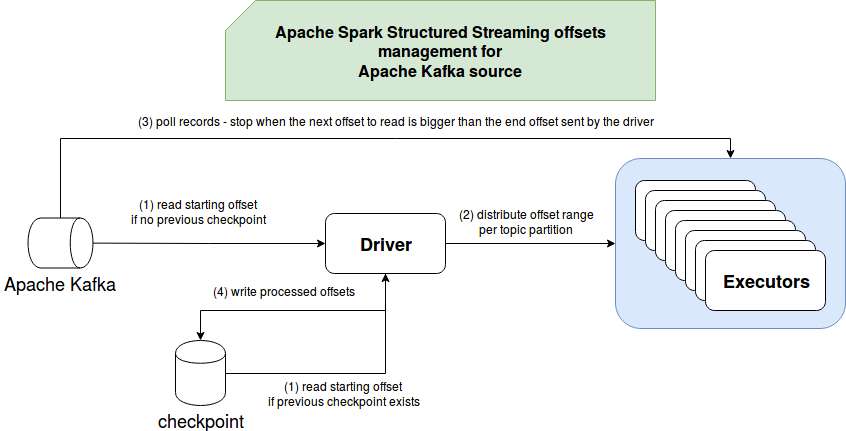
尽管这三个问题的答案似乎很明显,但始终值得对实现进行研究。 正如您可以通过代码片段在本文中学习的那样,结构化流忽略了 Apache Kafka 中的偏移量提交。 相反,它依靠 driver 端自己的偏移量管理,该管理器负责将偏移量分配给 executor,并在处理回合结束时(时刻或微批量)检查点。 如果您有类似本文中的问题,请随时提出。 我一直渴望学习新事物。