Spark Structured Streaming 中的查询指标
— 焉知非鱼长查询的重点之一是跟踪。知道查询的执行方式总是很重要的。在结构化流中,由于有了称为 ProgressReporter 的特殊对象,我们可以追踪此执行。
在本文中,我们将重点介绍 ProgressReporter 对象收集的指标。在第一部分中,我们将解释其生命周期以及一些实现细节。下一部分将涵盖公开的信息,而最后一部分将通过一些测试展示 ProgressReporter 的行为。
ProgressReporter #
首先,让我们定义这个著名的 ProgressReporter。它是 org.apache.spark.sql.execution.streaming 中的一个 trait,由 StreamExecution 抽象类直接继承,因此由其实现间接继承:org.apache.spark.sql.execution.streaming.continuous.ContinuousExecution 和 org.apache.spark.sql.execution.streaming.MicroBatchExecution。 ProgressReporter 的作用是提供一个接口,该接口一旦实现,便可以自由用于报告有关流查询执行情况的统计信息。
ProgressReporter 定义了严格的生命周期阶段:
1、一切开始于流查询触发器(处理时间或事件时间)执行时。触发器要做的第一件事是对 ProgressReporter 的 startTrigger 方法的调用。此方法使报告程序准备好累积刚刚开始执行的统计信息。
2、稍后,根据选择的流模式(微批或连续),报告器将记录有关几个不同步骤执行情况的统计信息。下一部分将详细介绍这些步骤。为此,它使用了方法 reportTimeTaken[T](triggerDetailKey: String)(body: => T),该方法将有关执行这些步骤的度量添加到 currentDurationsMs: mutable.HashMap[String,Long]` 字段中。
3、下一步是数据处理,报告者还将收集一些统计信息。
4、将这些统计信息添加到 currentDurationMs 映射后,如果执行微批处理,则 ProgressReporter 调用 finishTrigger(hasNewData: Boolean)。此方法完成触发器的执行,并创建保存执行统计信息的对象,这些统计信息放入 progressBuffer = new mutable.Queue[StreamingQueryProgress]() 中。之后,客户端可以通过公共访问器方法直接从那里检索更新(或最后一个更新)。
在 ProgressReporter 中,我们还可以找到其他一些指标,例如:
- newData - 它是一个
Map[BaseStreamingSource, LogicalPlan],其中包含每个源的最新数据。 - availableOffsets - 这是一个类似于 map 的
StreamProgress对象,用于存储未提交到接收器的可用于处理的偏移量。 - commitOffsets - 类似于 availableOffset。不同之处在于,它存储已处理和已提交数据的偏移量。
- currentBatchId - 当前处理批次的 ID。
- currentStatus - org.apache.spark.sql.streaming.StreamingQueryStatus 的实例,暴露查询的当前状态。它将信息公开为数据可用性或触发器活动标志。
- watermarkMsMap - 它不存在于 ProgressReporter trait 中,但值得一提,因为它由 StreamExecution 使用。此字段是一个 map(MutableMap[Int,Long]),其中的键表示物理计划中的运算符,并且值是以毫秒为单位的新水位。此 map 最后用于更新全局水位:
if(!watermarkMsMap.isEmpty) {
val newWatermarkMs = watermarkMsMap.minBy(_._2)._2
if (newWatermarkMs > batchWatermarkMs) {
logInfo(s"Updating eventTime watermark to: $newWatermarkMs ms")
batchWatermarkMs = newWatermarkMs
} else {
logDebug(
s"Event time didn't move: $newWatermarkMs < " +
s"$batchWatermarkMs")
}
}
- stateOperators - 通过 ProgressReporter 的 ExecutionStats case 类公开。 它们包含在度量测试期间发现的众所周知的度量:已处理的行数(numRowsTotal),更新的行数(numRowsUpdated)和有状态操作期间使用的内存(memoryUsedBytes)。
度量指标 #
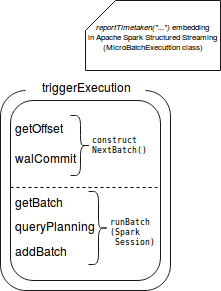
在这一部分中,我们重点介绍使用 reportTimeTaken[T](triggerDetailKey: String)(body: => T): T 度量的指标:
- triggerExecution - 报告给定触发器的执行时间,即偏移量检索,数据处理和 WAL 提交花费的时间
- queryPlanning - 在这里生成执行计划
- getBatch - 从可用源中检索新数据(仅微批)
- getOffset - 测量用于为每个已定义源处理新数据以获取偏移量的时间
- walCommit - 测量提交新的可用偏移量所花费的时间
- addBatch - 返回将数据发送到给定接收器所花费的时间
- runContunous - 它测量在连续处理模式下执行流查询所花费的时间
其中一些指标包括其他指标。 下图显示了此嵌入:
ProgressReporter 测试 #
现在,通过学习测试来研究 ProgressReporter 和其他一些先前提到的属性:
private val sparkSession: SparkSession = SparkSession.builder().appName("Spark Structured Streaming progress reporter")
.master("local[2]").getOrCreate()
import sparkSession.sqlContext.implicits._
"sample count aggregation per id" should "have corresponding metricss" in {
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
val aggregatedStream = inputStream.toDS().toDF("id", "name")
.groupBy("id")
.agg(count("*"))
val query = aggregatedStream.writeStream.trigger(Trigger.ProcessingTime(1000)).outputMode("complete")
.foreach(new NoopForeachWriter())
.start()
val progress = new scala.collection.mutable.ListBuffer[StreamingQueryProgress]()
new Thread(new Runnable() {
override def run(): Unit = {
var currentBatchId = -1L
while (query.isActive) {
inputStream.addData((1, "A"), (2, "B"))
Thread.sleep(1000)
val lastProgress = query.lastProgress
if (currentBatchId != lastProgress.batchId) {
progress.append(lastProgress)
currentBatchId = lastProgress.batchId
}
}
}
}).start()
query.awaitTermination(25000)
val firstProgress = progress(0)
firstProgress.batchId shouldEqual(0L)
firstProgress.stateOperators should have size 0
firstProgress.numInputRows shouldEqual(0L)
val secondProgress = progress(1)
secondProgress.batchId shouldEqual(1L)
// Below some metrics contained in the progress reported
// It's impossible to provide exact numbers it's why the assertions are approximate
secondProgress.durationMs.get("addBatch").toLong should be > 6000L
secondProgress.durationMs.get("getBatch").toLong should be < 1000L
secondProgress.durationMs.get("queryPlanning").toLong should be < 1000L
secondProgress.durationMs.get("triggerExecution").toLong should be < 11000L
secondProgress.durationMs.get("walCommit").toLong should be < 500L
secondProgress.stateOperators(0).numRowsTotal should be < 10L
secondProgress.stateOperators(0).numRowsTotal should be > 0L
secondProgress.stateOperators(0).numRowsTotal shouldEqual(secondProgress.stateOperators(0).numRowsUpdated)
secondProgress.stateOperators(0).memoryUsedBytes should be > 10000L
secondProgress.sources should have size 1
secondProgress.sources(0).startOffset shouldEqual("0")
secondProgress.sources(0).numInputRows should be >= 200L
secondProgress.sink.description shouldEqual("ForeachSink")
}
追踪数据处理工作的进度是一项重要的任务,尤其是在流管道的情况下。 尽快发现任何问题,便会更早解决它们,并且可能会减少开销。 Apache Spark 结构化流提供了一个非常有助于跟踪查询性能的对象。 如第一节所示,该对象是 ProgressReporter,它包含在触发器活动中。 它不仅公开了非常常见的度量作为已处理的行数,而且还公开了更复杂的度量,例如有状态聚合中的估计已用内存,更新的行数甚至是计划查询或检索要处理的新偏移量所花费的时间。