Spark Structured Streaming 中的状态聚合
— 焉知非鱼最近,我们发现了用于处理结构化流中状态聚合的状态存储的概念。但是那时我们还没有花时间在这些聚合上。按照承诺,现在将对其进行描述。 这篇文章开始于聚合与有状态聚合之间的简短比较。在本文结尾之后,直接进行了一些测试,这些测试说明了状态聚合。
聚合与有状态聚合 #
聚合是从多个值中计算单个值的操作。在 Apache Spark 中,这种操作的示例可以是 count 或 sum 方法。在流式应用程序上下文中,我们谈论有状态聚合,即具有这些值的状态的聚合在一段时间内逐渐增长。
在对结构化流中的输出模式,状态存储和触发器给出了解释之后,就更容易理解状态聚合的特殊性。如所告知的,输出模式不仅确定数据量,而且还决定是否可以丢弃中间状态(如果与水印一起使用的话)。然后,所有这些中间状态都保留在容错状态存储中。上一次触发器执行后,触发器会按固定的时间间隔执行状态计算,这些数据是从上一次触发器执行中累积的。以下架构显示了所有这些部分如何协同工作:
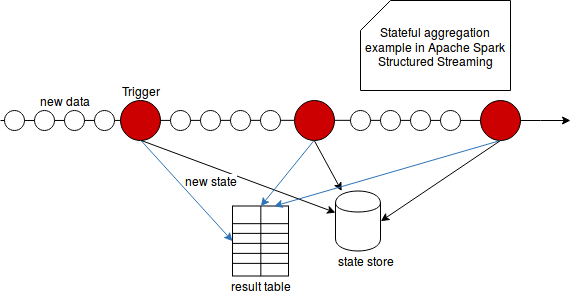
因此,为了简单起见,我们可以将状态聚合定义为结果随时间变化的聚合。 结果计算由触发器启动,并保存在状态存储中,在经过处理的数据通过水印之前(如果已定义),可以从状态存储中删除结果。
有状态聚合示例 #
两项测试显示了 Apache Spark 结构化流中的状态聚合:
"stateful count aggregation" should "succeed after grouping by id" in {
val testKey = "stateful-aggregation-count"
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
val aggregatedStream = inputStream.toDS().toDF("id", "name")
.groupBy("id")
.agg(count("*"))
val query = aggregatedStream.writeStream.trigger(Trigger.ProcessingTime(1000)).outputMode("update")
.foreach(
new InMemoryStoreWriter[Row](testKey, (row) => s"${row.getAs[Long]("id")} -> ${row.getAs[Long]("count(1)")}"))
.start()
new Thread(new Runnable() {
override def run(): Unit = {
inputStream.addData((1, "a1"), (1, "a2"), (2, "b1"))
while (!query.isActive) {}
Thread.sleep(2000)
inputStream.addData((2, "b2"), (2, "b3"), (2, "b4"), (1, "a3"))
}
}).start()
query.awaitTermination(25000)
val readValues = InMemoryKeyedStore.getValues(testKey)
readValues should have size 4
readValues should contain allOf("1 -> 2", "2 -> 1", "1 -> 3", "2 -> 4")
}
"sum stateful aggregation" should "be did with the help of state store" in {
val logAppender = InMemoryLogAppender.createLogAppender(Seq("Retrieved version",
"Reported that the loaded instance StateStoreId", "Committed version"))
val testKey = "stateful-aggregation-sum"
val inputStream = new MemoryStream[(Long, Long)](1, sparkSession.sqlContext)
val aggregatedStream = inputStream.toDS().toDF("id", "revenue")
.groupBy("id")
.agg(sum("revenue"))
val query = aggregatedStream.writeStream.trigger(Trigger.ProcessingTime(1000)).outputMode("update")
.foreach(
new InMemoryStoreWriter[Row](testKey, (row) => s"${row.getAs[Long]("id")} -> ${row.getAs[Double]("sum(revenue)")}"))
.start()
new Thread(new Runnable() {
override def run(): Unit = {
inputStream.addData((1, 10), (1, 11), (2, 20))
while (!query.isActive) {}
Thread.sleep(2000)
inputStream.addData((2, 21), (2, 22), (2, 23), (1, 12))
}
}).start()
query.awaitTermination(35000)
// The assertions below show that the state is involved in the execution of the aggregation
// The commit messages are the messages like:
// Committed version 1 for HDFSStateStore[id=(op=0,part=128),
// dir=/tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state/0/128] to file
// /tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state/0/128/1.delta
val commitMessages = logAppender.getMessagesText().filter(_.startsWith("Committed version"))
commitMessages.filter(_.startsWith("Committed version 1 for HDFSStateStore")).nonEmpty shouldEqual(true)
commitMessages.filter(_.startsWith("Committed version 2 for HDFSStateStore")).nonEmpty shouldEqual(true)
// Retrieval messages look like:
// Retrieved version 1 of HDFSStateStoreProvider[id = (op=0, part=0),
// dir = /tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state/0/0] for update
// (org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider:54)
// It proves that the state is updated (new state is stored when new data is processed)
val retrievalMessages = logAppender.getMessagesText().filter(_.startsWith("Retrieved version"))
retrievalMessages.filter(_.startsWith("Retrieved version 0 of HDFSStateStoreProvider")).nonEmpty shouldEqual(true)
retrievalMessages.filter(_.startsWith("Retrieved version 1 of HDFSStateStoreProvider")).nonEmpty shouldEqual(true)
// The report messages show that the state is physically loaded. An example of the message looks like:
// Reported that the loaded instance StateStoreId(/tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state,0,3)
// is active (org.apache.spark.sql.execution.streaming.state.StateStore:58)
val reportMessages = logAppender.getMessagesText().filter(_.startsWith("Reported that the loaded instance"))
reportMessages.filter(_.endsWith("state,0,1) is active")).nonEmpty shouldEqual(true)
reportMessages.filter(_.endsWith("state,0,2) is active")).nonEmpty shouldEqual(true)
reportMessages.filter(_.endsWith("state,0,3) is active")).nonEmpty shouldEqual(true)
// The stateful character of the processing is also shown through the
// stateful operators registered in the last progresses of the query
// Usual tests on the values
val readValues = InMemoryKeyedStore.getValues(testKey)
readValues should have size 4
readValues should contain allOf("2 -> 20", "1 -> 21", "1 -> 33", "2 -> 86")
}
"stateful count aggregation" should "succeed without grouping it by id" in {
val logAppender = InMemoryLogAppender.createLogAppender(Seq("Retrieved version",
"Reported that the loaded instance StateStoreId", "Committed version"))
val testKey = "stateful-aggregation-count-without-grouping"
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
val aggregatedStream = inputStream.toDS().toDF("id", "name")
.agg(count("*").as("all_rows"))
val query = aggregatedStream.writeStream.trigger(Trigger.ProcessingTime(1000)).outputMode("update")
.foreach(
new InMemoryStoreWriter[Row](testKey, (row) => s"${row.getAs[Long]("all_rows")}"))
.start()
new Thread(new Runnable() {
override def run(): Unit = {
inputStream.addData((1, "a1"), (1, "a2"), (2, "b1"))
while (!query.isActive) {}
Thread.sleep(2000)
inputStream.addData((2, "b2"), (2, "b3"), (2, "b4"), (1, "a3"))
}
}).start()
query.awaitTermination(25000)
// We can see that the same assertions as for the previous test pass. It means that the
// stateful aggregation doesn't depend on the presence or not of the groupBy(...) transformation
val commitMessages = logAppender.getMessagesText().filter(_.startsWith("Committed version"))
commitMessages.filter(_.startsWith("Committed version 1 for HDFSStateStore")).nonEmpty shouldEqual(true)
commitMessages.filter(_.startsWith("Committed version 2 for HDFSStateStore")).nonEmpty shouldEqual(true)
val retrievalMessages = logAppender.getMessagesText().filter(_.startsWith("Retrieved version"))
retrievalMessages.filter(_.startsWith("Retrieved version 0 of HDFSStateStoreProvider")).nonEmpty shouldEqual(true)
retrievalMessages.filter(_.startsWith("Retrieved version 1 of HDFSStateStoreProvider")).nonEmpty shouldEqual(true)
val reportMessages = logAppender.getMessagesText().filter(_.startsWith("Reported that the loaded instance"))
reportMessages.filter(_.endsWith("state,0,0) is active")).nonEmpty shouldEqual(true)
val readValues = InMemoryKeyedStore.getValues(testKey)
readValues should have size 2
readValues should contain allOf("3", "7")
}
这篇简短的帖子是 Apache Spark 结构化流中有状态数据处理的恢复。 发现输出模式,状态存储和触发器后,我们了解了有关状态聚合的更多信息。 实际上,它们与无状态聚合没有太大区别。 主要区别在于以下事实:计算值可以在随后的查询执行中更改,如第二部分的第一个测试所示。 这些中间结果存储在已经描述的状态存储中,这在同一部分的第二次测试中得到了证明。